CSAPP › CSAPP 3장 어셈블리 제어문(Week3_Day3)
오늘은 csapp3장을 이어서 공부했다.
제어문
반복문, 스위치문들은 조건부 실행이 요구됨. 기계어 코드에서 조건부 동작을 시행하는 법으론 데이터의 흐름 변경, 제어흐름의 변경 두 가지 방법이 있음. 먼저 제어 흐름에 대해서 알아볼 것.
조건 코드
cpu의 비교연산이나 테스트 연산 이후에 설정되는 cpu의 상태 플래그로 각 플래그는 1비트의 크기를 가지며 상태 레지스터나 플래그 레지스터에 저장됨. 이 레지스터들은 조건부 분기를 수행하기 위해 참고 됨.
RFLAGS : cpu의 상태를 나타내는 플래그 비트들이 저장되는 64비트 레지스터로 x86_64에서는 상태 레지스터와 플래그 레지스터 모두의 대표적인 예시로 같은 개념을 지칭함.
조건 코드의 대표적 종류
CF(Carry flag) : unsigned number의 덧셈과 뺄셈에서 올림 또는 빌림이 발생하면 설정되는 플래그.
올림 : 덧셈을 했을 때 표현 가능한 범위를 넘어서면 발생. ex) 0xFFFFFFFF(32비트의 최대 수) + 1 을 하게 되면 33비트의 수(0x100000000) 가 나오지만 이를 32비트로 표현하게 되면 상위 1비트가 잘린 0x00000000 즉 0 이 되어버린다.
빌림 : 뺄셈을 했을 때 음수가 나오면 발생. 실제로 음수 표현이 32비트를 넘어서는 것이 아니라, 음수 결과는 signed number로 해석 되기 때문에 32비트 unsigned number로는 표현 할 수 없어 플래그가 발생함.
- ZF(Zero flag) : 연산의 결과가 0이 되었을 때 설정되는 플래그.
- SF(Sign flag) : signed number에 대해서 연산의 결과가 음수가 발생하면 설정되는 플래그.
- OF(Overflow flag) : signed number의 연산에서 2의 보수 오버 플로우가 발생하면 설정되는 플래그.
2의 보수 : 음수를 표현할 때 2진법으로 나타낸 뒤 1을 더하여 음수를 표현하는 방법.
ex) 8비트 signed number 에서 덧셈의 경우 127(0111 1111) 최대 양수 값에 1(0000 0001)을 더했을 때, 128이 되어야 하지만, 최대 값을 초과 하여 음수 범위로 넘어가기 때문에 -128(1000 0000)이 될 경우. 오버플로우가 발생함. 뺄셈의 경우에는 -128(1000 0000) 에서 -1(1111 1111)을 하게 되면 127(0111 1111)이 되어 오버플로우가 발생함. 이렇듯 양수 + 양수 = 음수 또는 음수 + 음수 = 양수가 되었을 경우 오버플로우가 발생함.
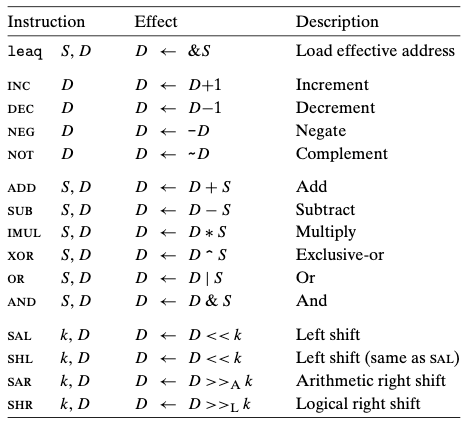
그림의 인스트럭션 중 leaq는 주소 계산에 사용하기 위한 것으로 조건 코드를 변경 시키지 않음. 이를 제외한 모든 인스트럭션들은 조건 코드 값을 변경시킴.
- XOR 같은 논리 연산에서 캐리와 오버플로우 플래그가 0으로 세팅.
- 쉬프트 연산에서는 캐리 플래그가 쉬프트 되어 없어지는 마지막 비트로 설정, 오버플로우 플래그는 0으로 세팅.
위의 플래그들은 산술연산(arithmetic operation)의 부가 결과 처럼 암시적으로(implicit)하세 설정 됨. 하지만 이 조건 코드들을 명시적으로(explicit)하게 프로그래머가 직접 설정하고 해제 할 수 있게 해주는 instruction이 존재함.
CMP(compare)
 CMP 명령어는 두 오퍼랜드(레지스터, 메모리주소, 즉시값)을 비교하여 뺄셈을 수행하지만, 그 결과는 저장하지 않고(뺄셈 연산을 destination없이 수행하는 것과 같음) 플레그 레지스터에 해당하는 플래그를 설정함. 이 때, 두 오퍼랜드가 주어지는 순서가 일반적인 연산의 반대로 주어짐.(보통 연산에서 src, dest 순서로 주어진다면 여기선 dest, src순서로 주어짐) 그렇기 때문에 그림에서와 같이 $S_{1}$, $S_{2}$가 주어진다면 $S_{2}-S_{1}$라고 적어보는게 도움 됨.
CMP 명령어는 두 오퍼랜드(레지스터, 메모리주소, 즉시값)을 비교하여 뺄셈을 수행하지만, 그 결과는 저장하지 않고(뺄셈 연산을 destination없이 수행하는 것과 같음) 플레그 레지스터에 해당하는 플래그를 설정함. 이 때, 두 오퍼랜드가 주어지는 순서가 일반적인 연산의 반대로 주어짐.(보통 연산에서 src, dest 순서로 주어진다면 여기선 dest, src순서로 주어짐) 그렇기 때문에 그림에서와 같이 $S_{1}$, $S_{2}$가 주어진다면 $S_{2}-S_{1}$라고 적어보는게 도움 됨.Test Compare 명령어가 두 오퍼랜드의 비교결과를 알고 싶었던 거라면 Test 명령어는 주로 하나의 오퍼랜드가 음수인지, 0인지를 알고 싶을 때 사용함. 비트 단위의 AND 연산을 수행해서 그 결과를 저장하지 않고, 플래그 레지스터에 해당 플레그를 설정함.
비트연산 : 비트를 개별적으로 연산.
- AND 연산 (&) : 두 비트가 모두 1일 때만 1을 반환 ex) 0101 AND 0011 = 0001
- OR 연산 (|) : 두 비트 중 하나라도 1일 때 1을 반환 ex) 0101 OR 0011 = 0111
- XOR 연산 (^) : 두 비트가 서로 다를 때 1을 반환 ex) 0101 XOR 0011 = 0110
- NOT 연산 (~) : 비트를 반전(1을 0으로, 0을 1로). ex) NOT 0101 = 1010
조건코드의 사용법 이론적으로 상태 레지스터에서 특정 코드 값을 가져와서 사용할 수 있으나 보통은 그렇게 사용하지 않음.
- Set Instruction : 조건의 조합에 따라 하나의 레지스터에 1바이트로 0 또는 1을 기록.
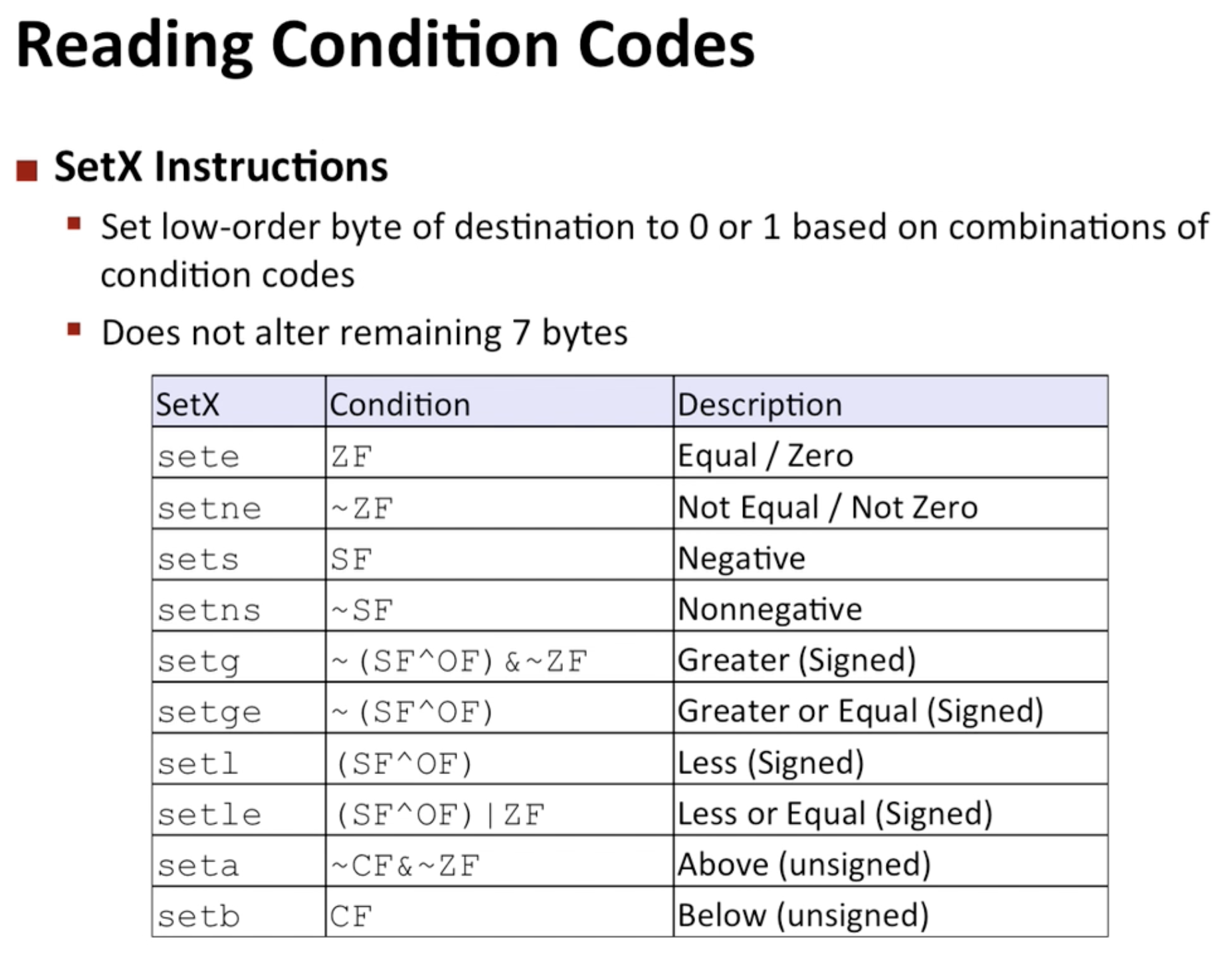 이 때 주의할 점은 인스트럭션의 접미어를 통해 word, byte 등의 오퍼랜드의 크기를 나타내는 것이 아니라, 어떤 조건 코드의 조합을 사용할 것인지, setl의 경우 set less, setb의 경우 set below를 의미한다는 것에 주의 해야 함. 그렇다면 1byte의 크기를 어떻게 처리하냐?
이 때 주의할 점은 인스트럭션의 접미어를 통해 word, byte 등의 오퍼랜드의 크기를 나타내는 것이 아니라, 어떤 조건 코드의 조합을 사용할 것인지, setl의 경우 set less, setb의 경우 set below를 의미한다는 것에 주의 해야 함. 그렇다면 1byte의 크기를 어떻게 처리하냐?  16개의 레지스터 각각에 대해서 최하위의 바이트에 0 또는 1을 임의로 설정할 수가 있으며, 이는 나머지 7바이트에 영향을 주지 않음.
16개의 레지스터 각각에 대해서 최하위의 바이트에 0 또는 1을 임의로 설정할 수가 있으며, 이는 나머지 7바이트에 영향을 주지 않음.  이 어셈블리 코드를 보면 x, y에 대한 비교연산을 수행하고, setg 인스트럭션을 통해 더 클 경우에 1을 설정한다는 것을 알 수있음. 그 과정에서 %al에 1을 저장하는데 이는 %rax의 하위 1바이트임. 보통 %rax는 return value를 설정하는데 사용 한다는 것을 알 수 있음. 만약 32비트 또는 64비트의 결과를 만들고 싶다면 movzbl 같은 인스트럭션을 사용해서 %rax의 나머지 바이트들도 0 또는 1로 설정 할 수 있음.
이 어셈블리 코드를 보면 x, y에 대한 비교연산을 수행하고, setg 인스트럭션을 통해 더 클 경우에 1을 설정한다는 것을 알 수있음. 그 과정에서 %al에 1을 저장하는데 이는 %rax의 하위 1바이트임. 보통 %rax는 return value를 설정하는데 사용 한다는 것을 알 수 있음. 만약 32비트 또는 64비트의 결과를 만들고 싶다면 movzbl 같은 인스트럭션을 사용해서 %rax의 나머지 바이트들도 0 또는 1로 설정 할 수 있음.movzbl(Move with Zero-Extend Byte to Long) : 특정 레지스터의 하위 1바이트를 가져와서 새로운 레지스터에 왼쪽을 0으로 채워서 저장함. 위의 예시에서는 %al의 값을 가져와서 %eax에 저장했음.
그럼 여기서 32비트까지만 0 또는 ㅂ이여야지 왜 %rax가 모두 0 이냐고 한다면 x86_64에서는 연산결과가 32비트일경우 나머지 32비트에 0을 추가함. 그렇기 때문에 4바이트 instruction은 상위 바이트 들을 0으로 설정함.
- 조건부 분기 :
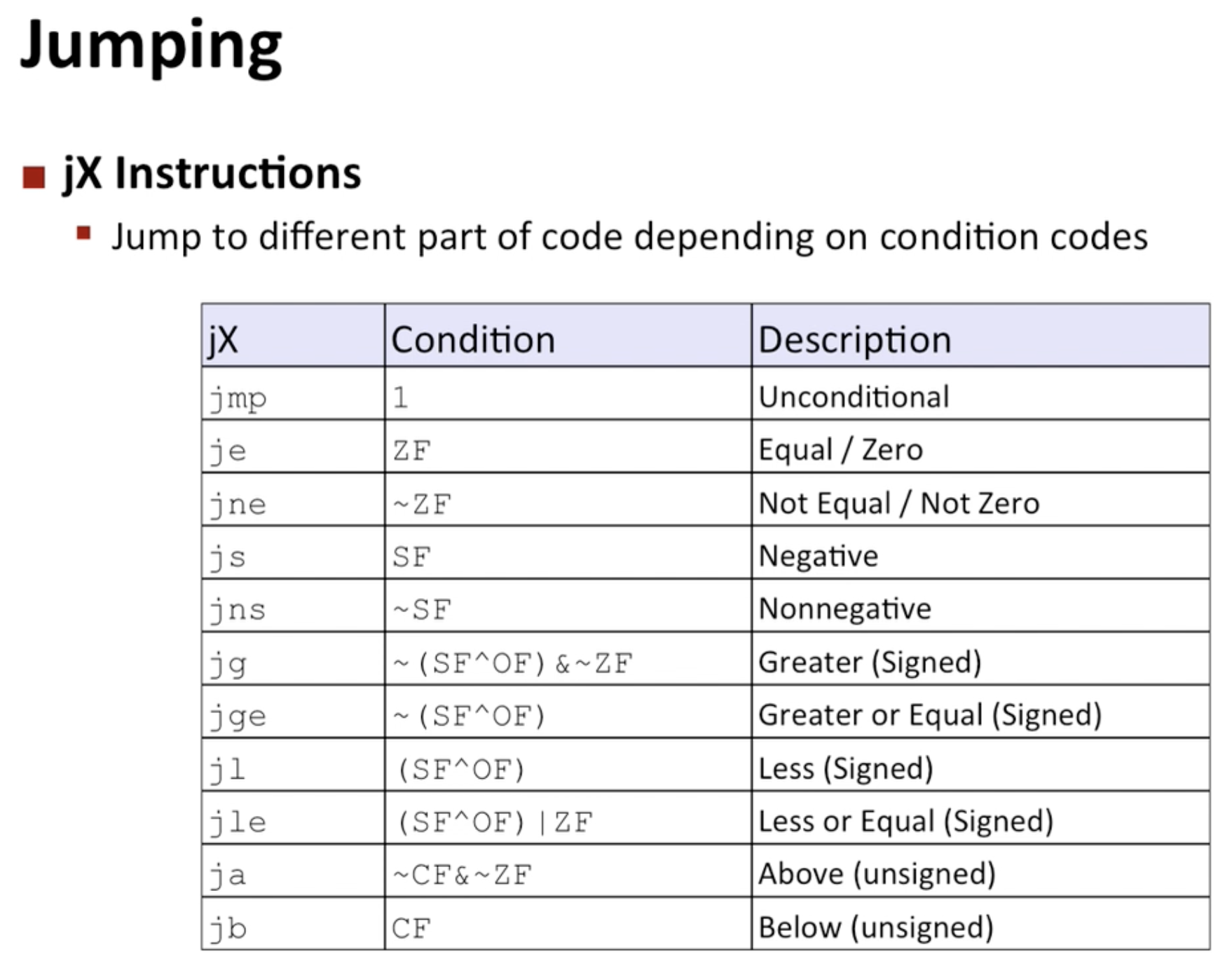
- Jump Instruction : 보통 인스트럭션은 순차적으로 실행이 되지만, 점프 인스트럭션을 사용하면 특정 위치로 건너뛰거나 다시 돌아오는 것이 가능.
- unconditional jump : 조건에 관계없이 jump하라고 하면 바로 jump
- conditional jump : 조건이 맞아야지만 jump

위 사진은 jump instruction을 이용한 분기 처리를 보여주는 예시임(x, y의 차이의 절댓값을 구함). x > y일 때는 x - y를 return 하고, x <= y 일때는 y - x를 return 하고싶다는 것임.
이 때 “.L4:” 와 같이 :(콜론)옆에 있는 게 label이라고 칭하며, 오브젝트코드에서는 보이지 않고 어셈블리 코드에서만 보이는 태그로 점프했을 때 어디로 가야할 지 주소를 나타내는 지표임.
return value를 나타낼 때는 따로 처리를 할 필요가 없고 %rax에 저장해 놓으면 호출한 함수에서 아 return 값이구나 하고 찾아감.
goto statement : 어셈블리 코드를 보다보면 어지러움. 그래서 C를 이용해서 좀 더 추상화가 된 보기 편한 형태로 표현한 것.


- 조건부 이동
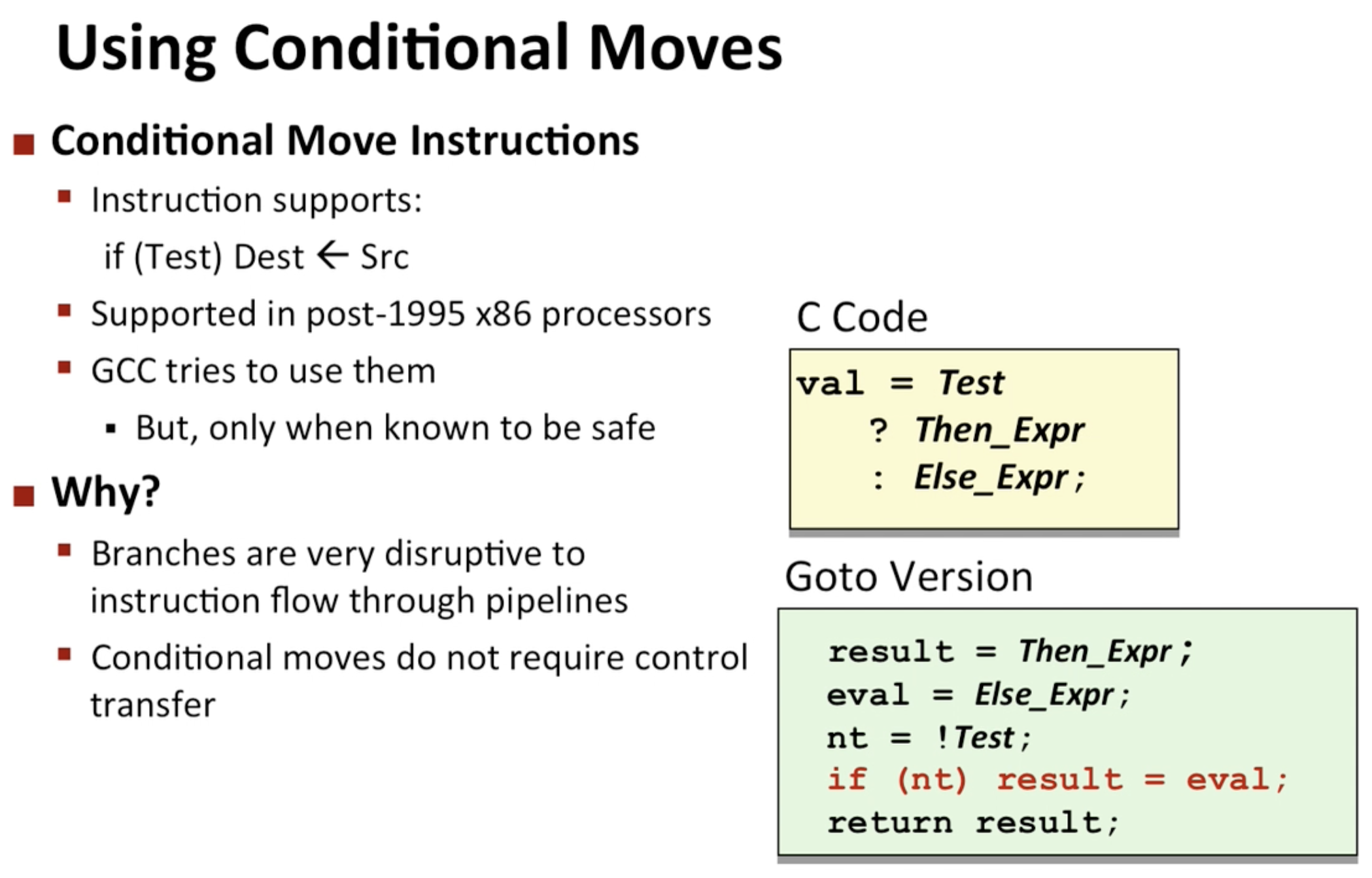 분기가 나뉠 때 두가지 모두에 대해서 연산을 수행하고 둘 중 하나만 선택하는 것.
분기가 나뉠 때 두가지 모두에 대해서 연산을 수행하고 둘 중 하나만 선택하는 것.(이짓을 왜함????) : 프로세스를 실행하면 이 프로세스는 관성이 있는 것 마냥 쭈욱 나아가려고 함. 이를 pipelining이라고 부르는데, 한 인스트럭션이 끝나기도 전에 다른 인스트럭션을 불러와서 계산하고 있는 행위를 의미함. 그러다가 분기를 만나면 찍음(branch prediction).(?????) 그런데 이게 꽤 정확하다고 함. 그런데 만약 틀린다면? 한참 돌아와서 다시가야함. 이것보다는 차라리 그리 비용이 비싼 연산이 아니라면 모두 진행하다가 맞는 것을 선택하는 것이 더 효율적이라는 결론에 도달한 것.
조건부 이동이라 불리는 이유는 eval(else value)를 조건이 통과 될 때만 result에 저장하기 때문. 앞선 jump instuction을 사용할 때는 명령어를 통해 conditional move를 사용하지 마라고 정해줬어야함. (앞선 그림을 보면 명령어가 있음, 컴퓨터는 겁내 쓰고 싶어함)

어셈블리 코드에서 알 수 있듯이 두 연산을 모두 수행한 뒤 conditional move를 통해 조건을 통과 한다면 result의 값을 업데이트 하고 있음.  만약 위 3가지 처럼 - 너무 비싼 계산 비용 - null pointer reference 등의 위험한 계산 - 프로그램의 상태를 변형시킬 수 있는 계산 이런 계산들의 경우에는 conditional move를 사용하지 않음.
만약 위 3가지 처럼 - 너무 비싼 계산 비용 - null pointer reference 등의 위험한 계산 - 프로그램의 상태를 변형시킬 수 있는 계산 이런 계산들의 경우에는 conditional move를 사용하지 않음.
반복문 C에는 3가지 반복문이 있는데 각각 while, for, do-while임.
Do-While
 일반적인 while문이 뒤집어진 것과 유사한데, 조건을 검사하는 부분이 위가 아니라 아래에 있음. 이를 goto로 나타내면 조건을 통과한다면 다시 loop로 점프해서 loop를 반복할지 탈출할 지를 정한다는 것을 알 수 있음.
일반적인 while문이 뒤집어진 것과 유사한데, 조건을 검사하는 부분이 위가 아니라 아래에 있음. 이를 goto로 나타내면 조건을 통과한다면 다시 loop로 점프해서 loop를 반복할지 탈출할 지를 정한다는 것을 알 수 있음.  위 코드의 어셈블리어 버전이니 jump하는 부분에 주의해서 읽어 볼 것.
위 코드의 어셈블리어 버전이니 jump하는 부분에 주의해서 읽어 볼 것.  이것이 일반형.
이것이 일반형.While
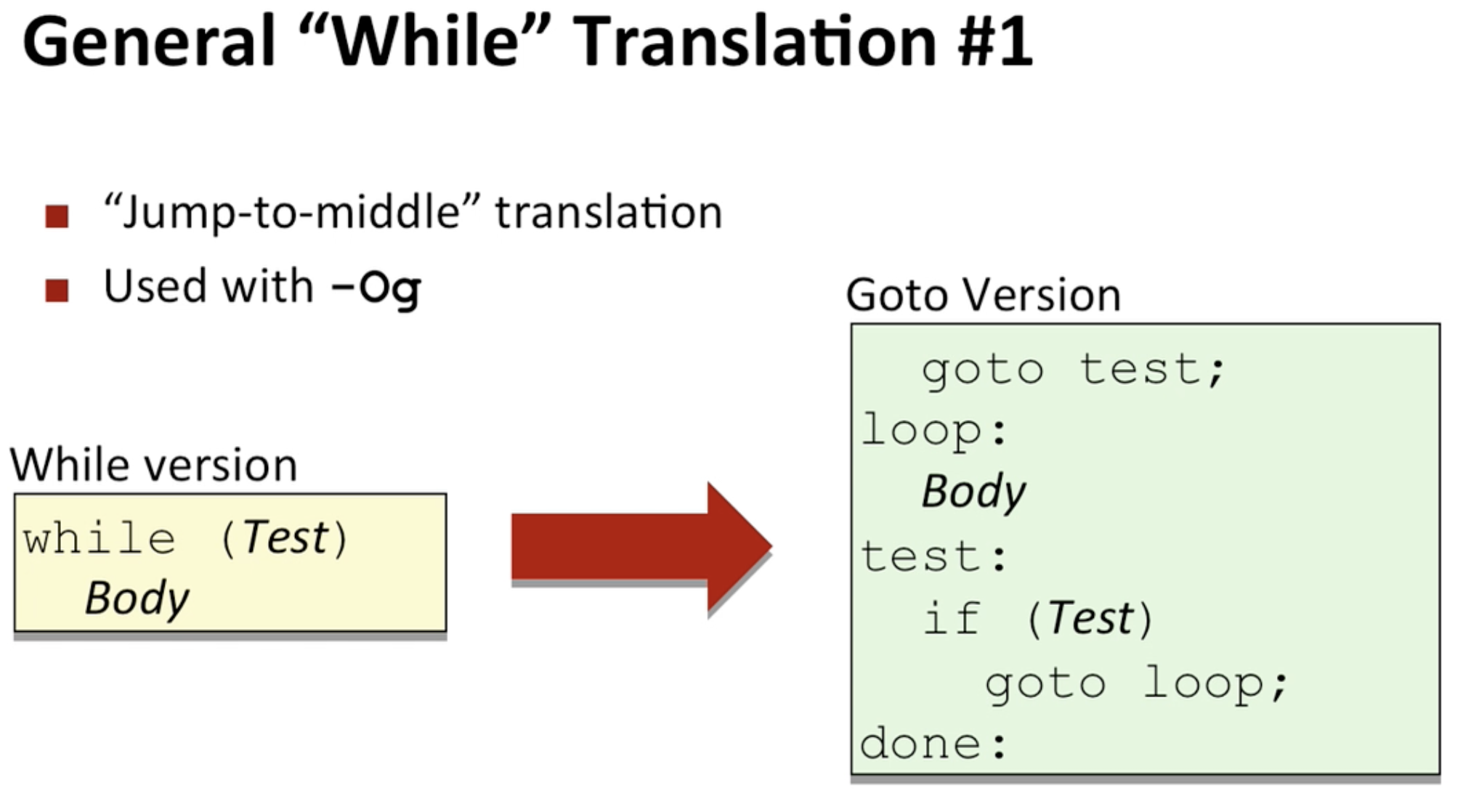
optimizatnion g를 이용했을 때의 표현 법. 보통은 O2를 많이 사용한다고 함.
do-while과의 가장 큰 차이점은 전자는 test의 통과 여부에 관계없이 무조건 한 번은 body가 실행된다는 점이고, while의 경우는 test를 통과하지 못하면 바로 loop를 스킵해버림.  jump to middile 이라고 표현하는 이유는 goto test를 만나 body로 가기전에 test부터 수행하고 loop으로 다시 점프하기 때문임.
jump to middile 이라고 표현하는 이유는 goto test를 만나 body로 가기전에 test부터 수행하고 loop으로 다시 점프하기 때문임. 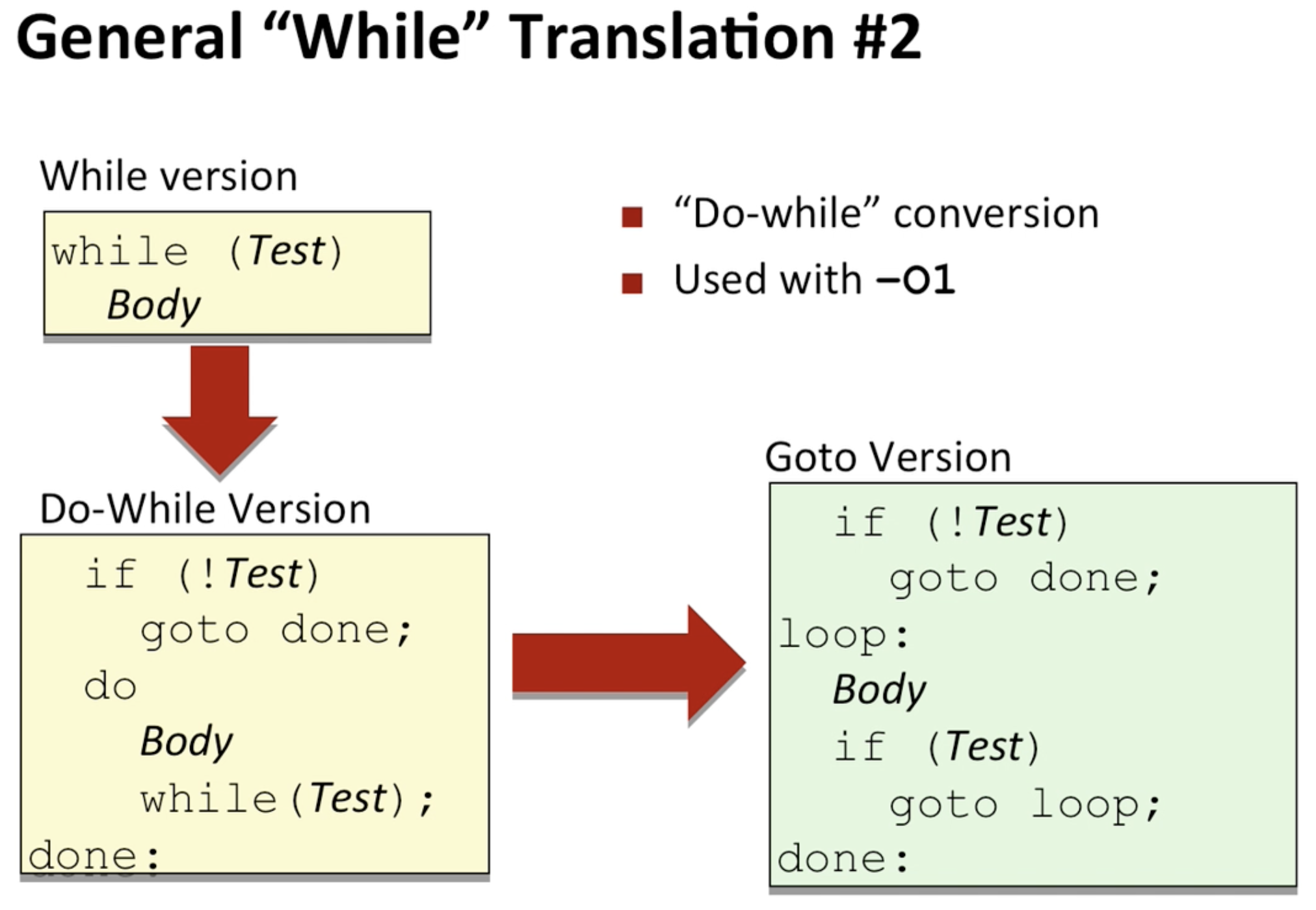
optimization O1을 사용했을 때의 표현법.

이 때는 do-while문으로 표현을 했음. 초기에 테스트를 한 번 추가 함으로서 테스트를 통과하면 일반 do-while문 처럼 작동하고, test를 통과하지못하면 통채로 스킵함.
for
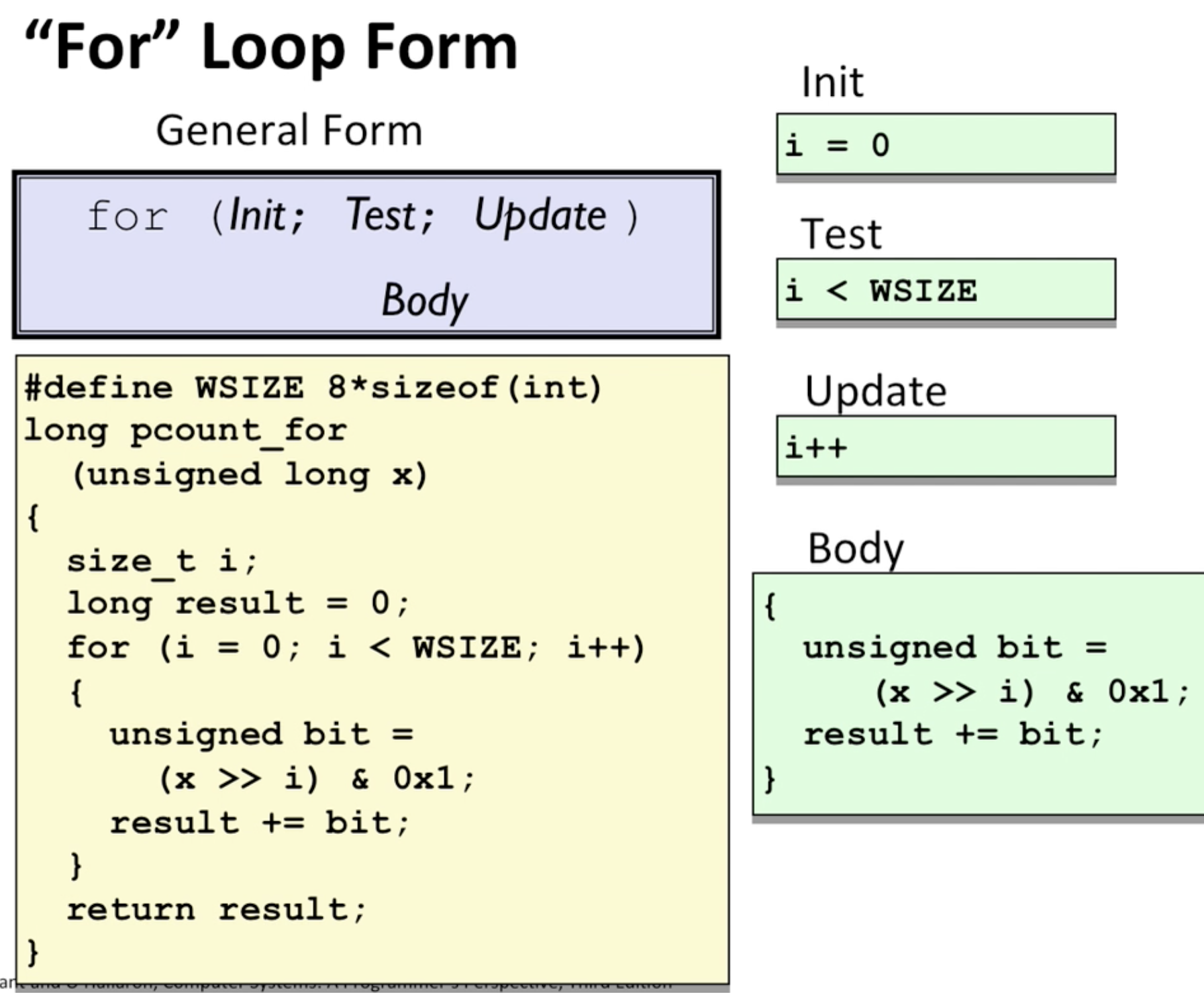 intialization, test, update(loop를 지속하기위한), body를 가짐.
intialization, test, update(loop를 지속하기위한), body를 가짐. 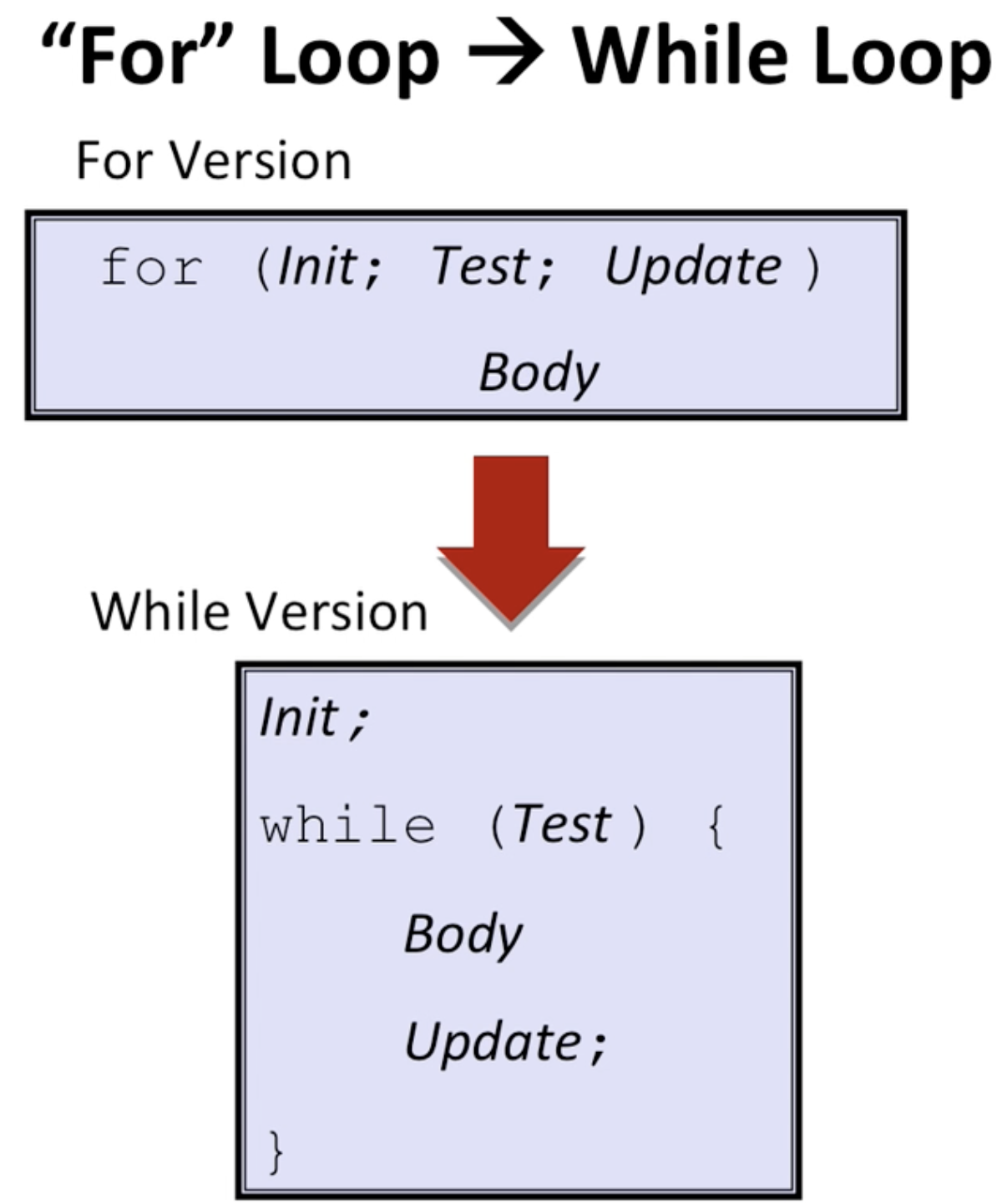
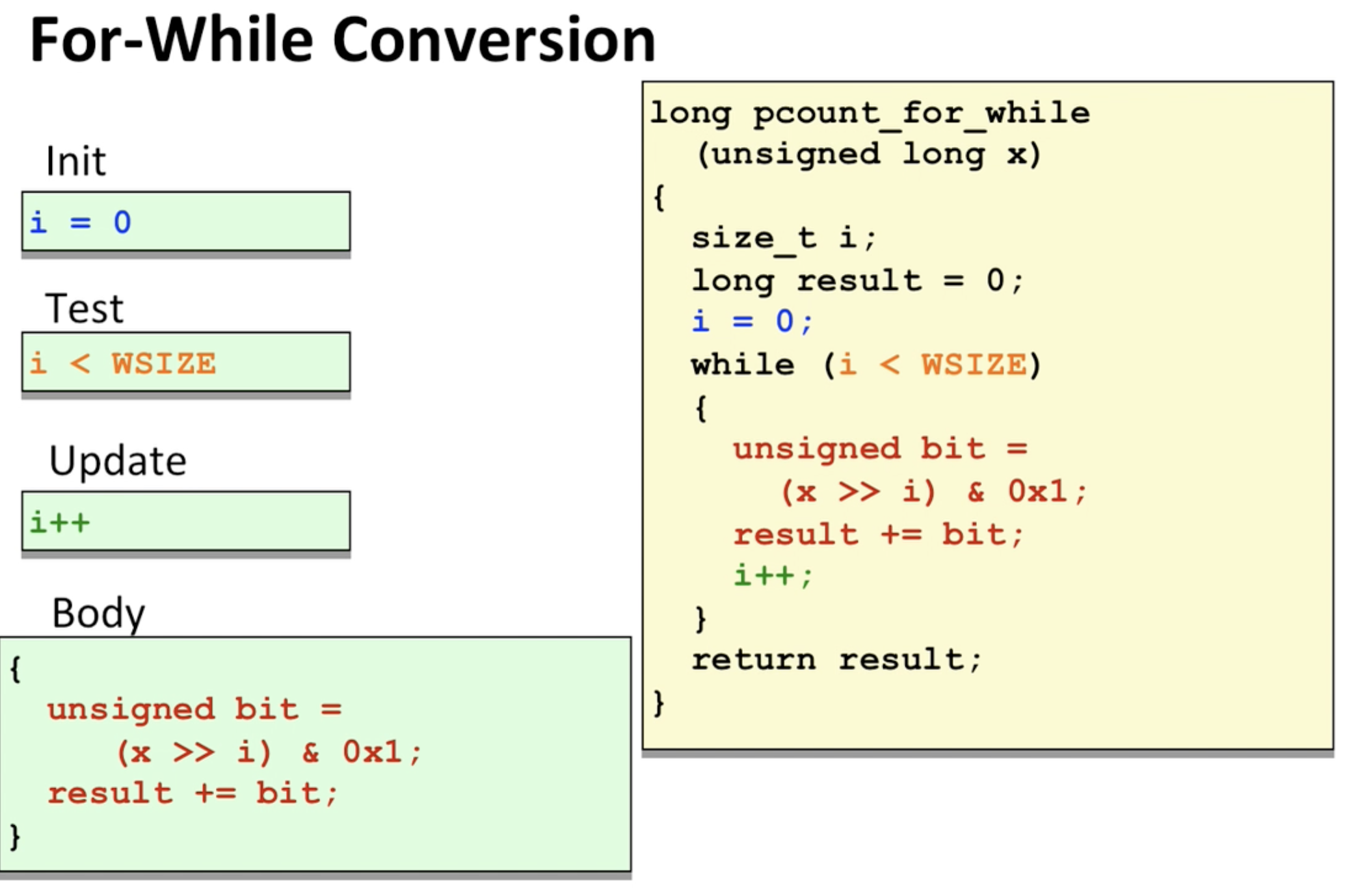 C에서는 for loop를 while loop로 해석.
C에서는 for loop를 while loop로 해석.  이 때 코드를 살펴보면 init을 할 때, !Test코드는 당연히 참이 될 가능성이 높다는 것을 알 수 있음. 이때는 아예 스킵을 해버림.
이 때 코드를 살펴보면 init을 할 때, !Test코드는 당연히 참이 될 가능성이 높다는 것을 알 수 있음. 이때는 아예 스킵을 해버림.Switch 문
 여기서 주의 할 점은 각 case마다 break를 넣어주지 않으면, fall through라고 적혀있는 부분처럼 그냥 다음 케이스로 넘어가버림. 그리고 모든 case를 만족하지 않을 경우를 위해 default가 존재함.
여기서 주의 할 점은 각 case마다 break를 넣어주지 않으면, fall through라고 적혀있는 부분처럼 그냥 다음 케이스로 넘어가버림. 그리고 모든 case를 만족하지 않을 경우를 위해 default가 존재함.
이 switch 문을 위해서 jump table structure를 사용함.
Jump Table Structure :
switch문의 각 case들의 코드들을 하나의 블럭씩(target)으로 생각을 하고, jump table이라는 함수 포인터 배열 또는 주소 배열을 정의 함. 각 포인터 또는 주소는 코드블록들을 가리키고, 위에서부터 조건을 하나씩 평가하면서 블록에 접근하는 것이 나닌, 메모리 주소를 가지고 직접적으로 jump(배열 인덱스의 사용)하기 때문에 훨씬 효율적임.

어셈블리어로 표현한 걸 보면, cmpq에서 6과 x를 비교하는데 이때 6인 이유는 예제에서 최대 케이스가 6이였기 때문임. 그리고 ja를 사용한 것이 포인트인데, jg를 사용했다면 signed compare이기 때문에 같이 작용하지 않을 것임. ja를 사용했기 때문에 unsigned compare가 되어서 6보다 x가 클 경우 뿐아니라, x가 0보다 작아서 음수가 나왔을 때도 unsigned연산에서 매우 큰 수로 받아들이기 때문에 L8 즉 default로 가게 되는 것. 이 때 w는 아직 사용하지 않기 때문에 gcc가 아 아직 안쓰니까 이따 code block에서 쓰면 init할게 ~ 하는 것. 마지막 줄이 앞서 말했던 jump table을 사용하는 부분인데,  이 때 jump table은 어셈블리 코드에서 구조가 만들어 져있지만 어셈블러가 그 값을 채워넣음. 이때 어셈블리 코드에서 어셈블러에게 quad크기의 value가 필요하고, 이 값들은 L8 등의 레이블을 가리킬 주소 value여야 한다고 알려줌.
이 때 jump table은 어셈블리 코드에서 구조가 만들어 져있지만 어셈블러가 그 값을 채워넣음. 이때 어셈블리 코드에서 어셈블러에게 quad크기의 value가 필요하고, 이 값들은 L8 등의 레이블을 가리킬 주소 value여야 한다고 알려줌. 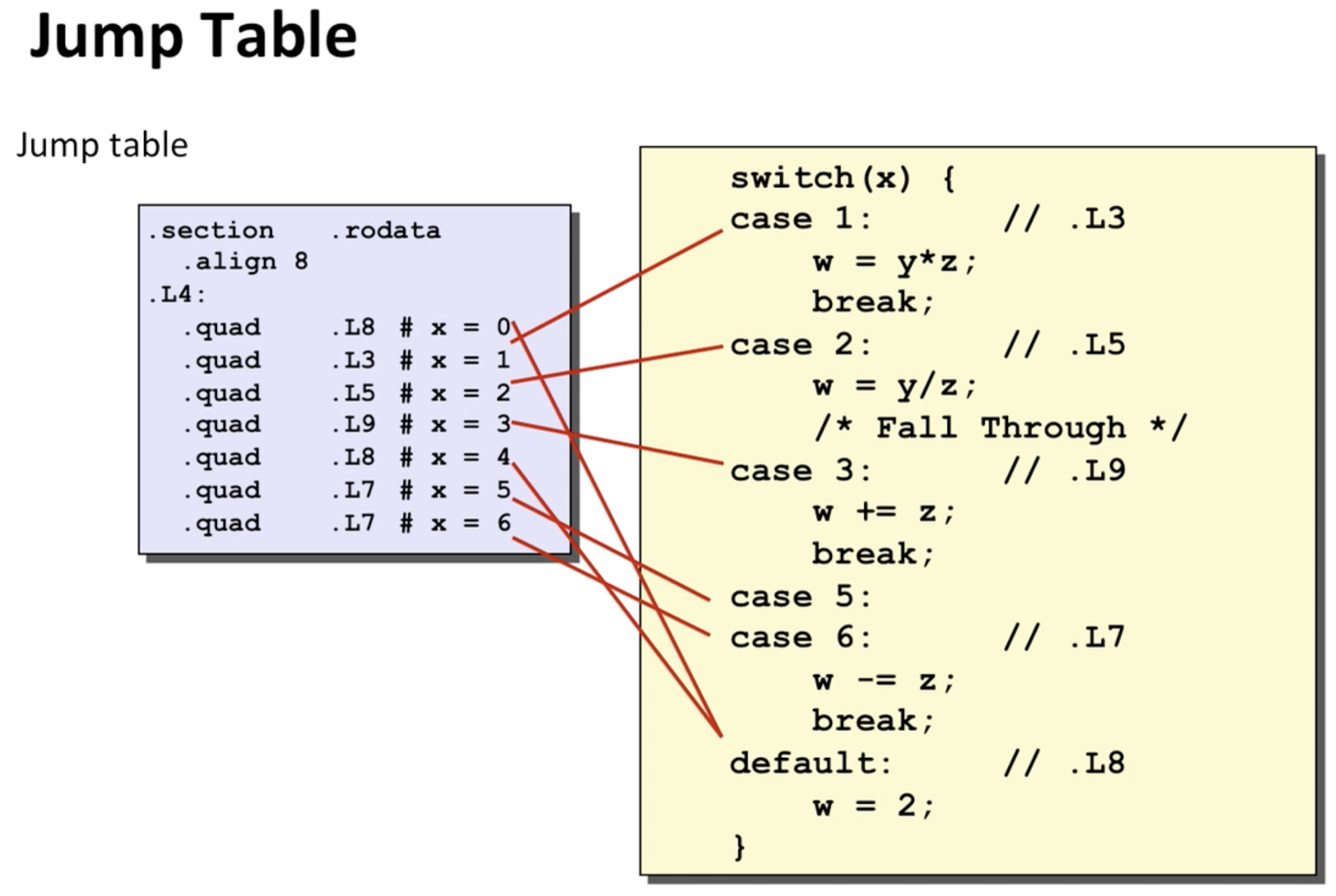 그림을 보면 case0와 case4은 존재 하지 않기 때문에 default로 가는 것을 알 수 있음. 그리고 앞서 ja로 점프할 위치였던 L8이 default 케이스의 코드블럭이 있는 곳임을 알 수 있음. 그리고 case5는 비어있기 때문에 case5, 6 모두 L7이 주어짐.
그림을 보면 case0와 case4은 존재 하지 않기 때문에 default로 가는 것을 알 수 있음. 그리고 앞서 ja로 점프할 위치였던 L8이 default 케이스의 코드블럭이 있는 곳임을 알 수 있음. 그리고 case5는 비어있기 때문에 case5, 6 모두 L7이 주어짐.  위 그림을 보면 각 코드 블럭마다 return이 있음을 알 수 있는데, 코드에서 마지막에 return w가 있긴 했지만, 그렇다고 자 이제 다같이 return 하자~가 아니라 break를 통해서 매번 return을 함.
위 그림을 보면 각 코드 블럭마다 return이 있음을 알 수 있는데, 코드에서 마지막에 return w가 있긴 했지만, 그렇다고 자 이제 다같이 return 하자~가 아니라 break를 통해서 매번 return을 함. 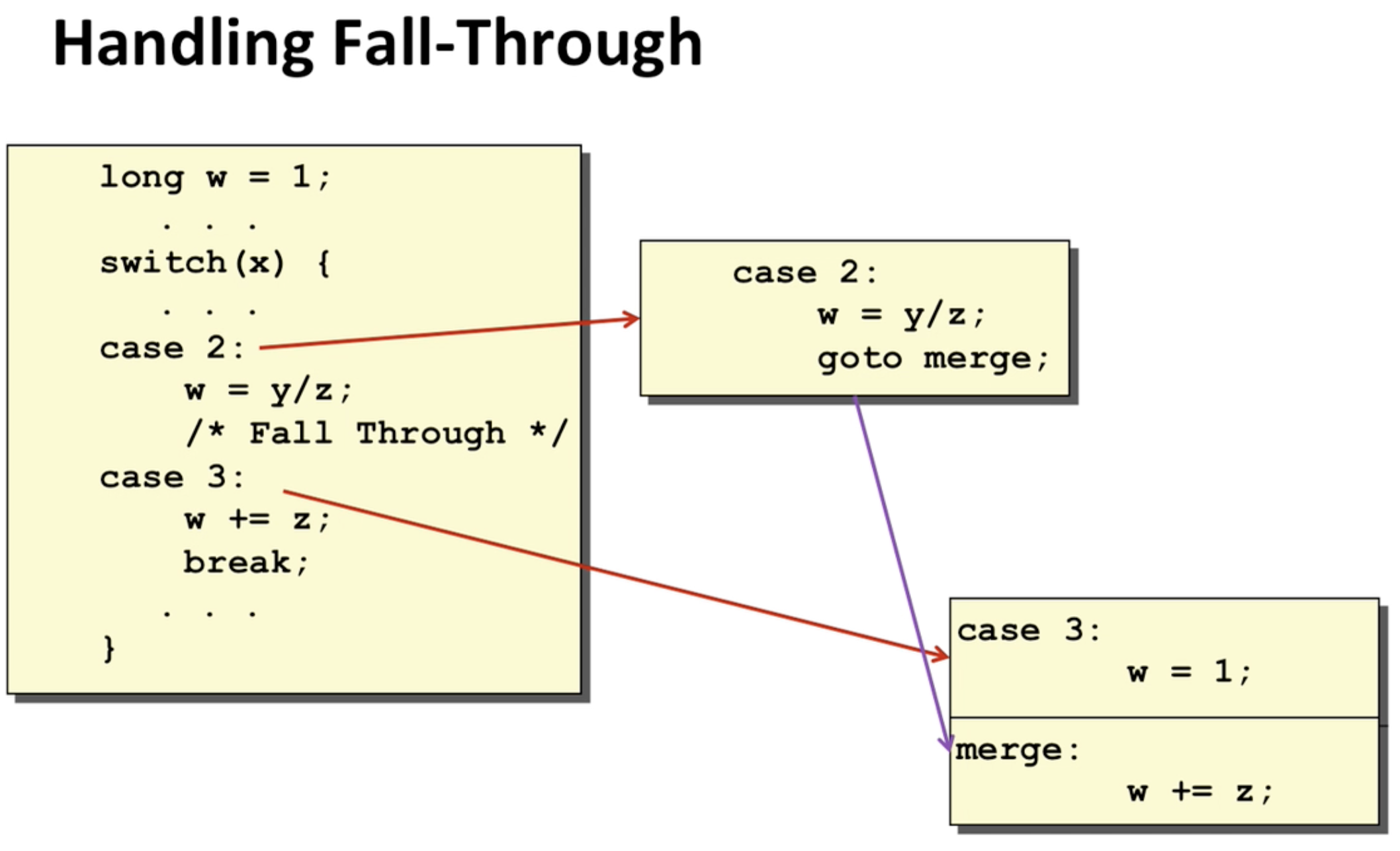 fall through 를 핸들링 할 때 보면 이때까지 w를 init하고 있지 않다가 case3에서 갑자기 필요해지니까 어머 하고 선언함. 그리고 case에서는 그 중간에 뛰어넘어서 merge함.
fall through 를 핸들링 할 때 보면 이때까지 w를 init하고 있지 않다가 case3에서 갑자기 필요해지니까 어머 하고 선언함. 그리고 case에서는 그 중간에 뛰어넘어서 merge함. 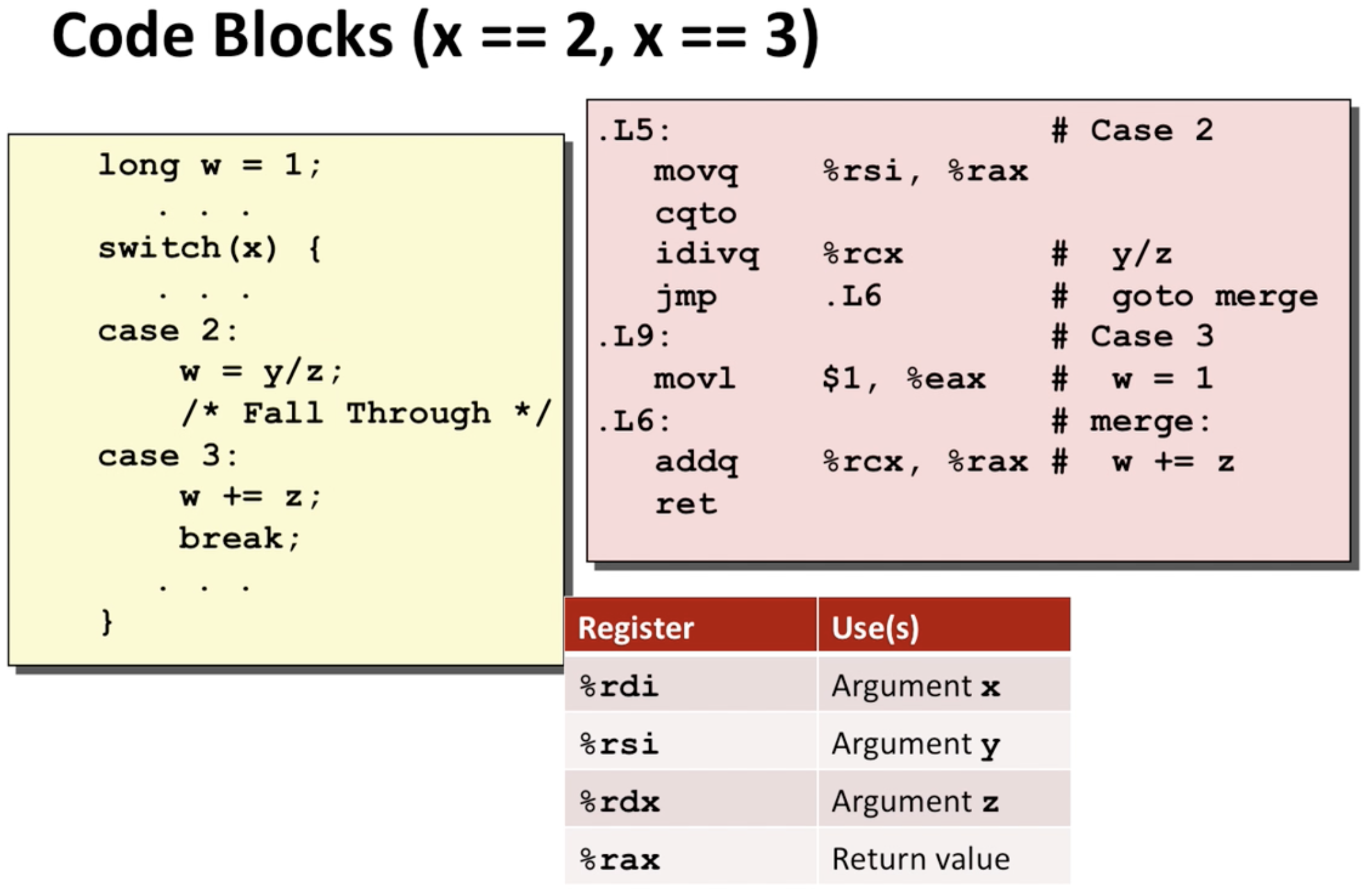
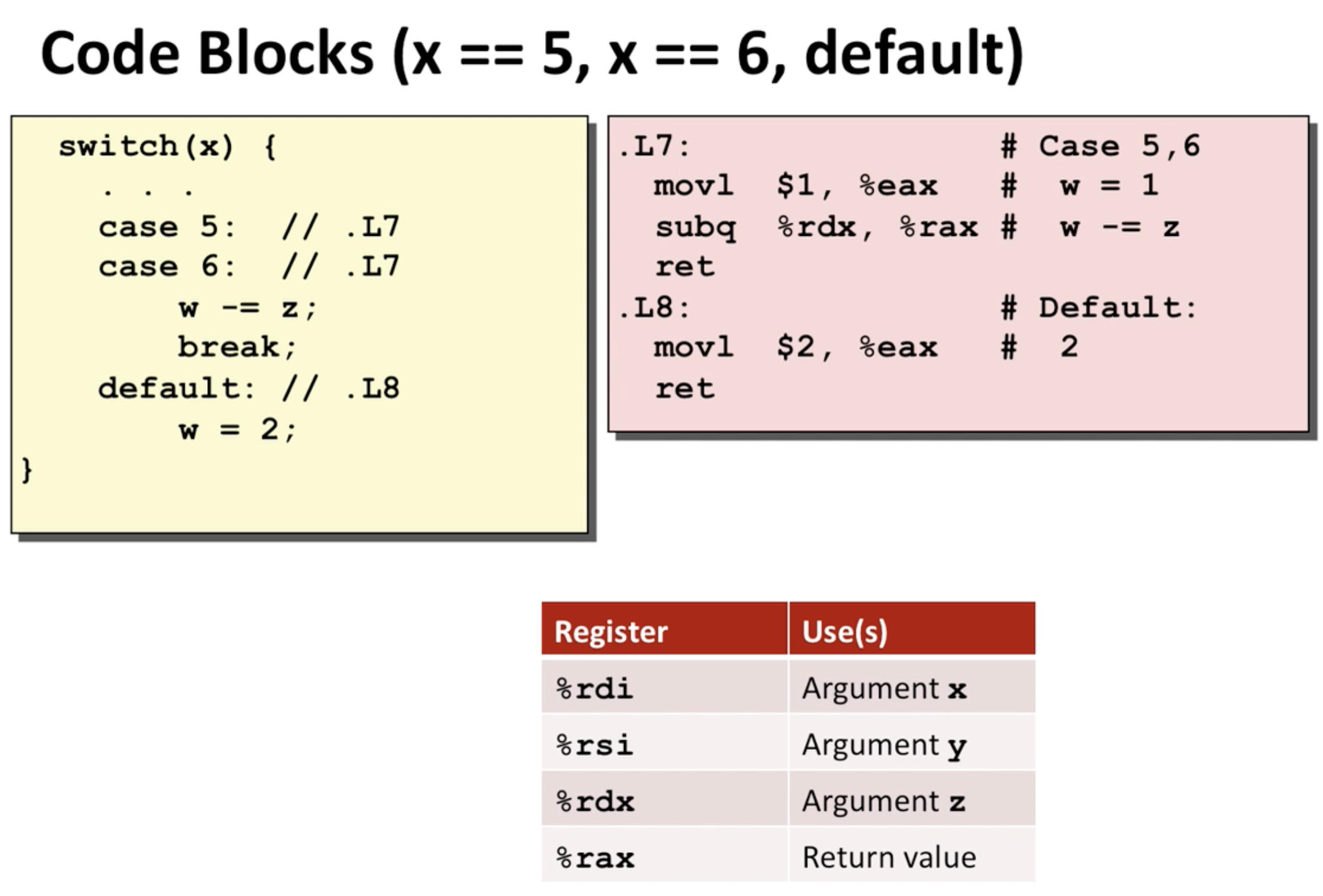 여기서도 보면 w = 1이 필요했기때문에 어머~ 하고 선언하는 모습을 볼 수 있음.
여기서도 보면 w = 1이 필요했기때문에 어머~ 하고 선언하는 모습을 볼 수 있음. 
출처 : csapp저자 강의