PYTHON › 파이썬으로 알아본 자료구조(Week1_Day5)
오늘은 파이썬의 자료구조에 대해 알아보았다.
스택(Stack)
말미잘 같은 자료구조이다. 입으로 들어와서 입으로 뱉듯이, 한쪽으로 들어와서 한쪽으로만 나간다. 세로로 긴 관에 사탕을 색깔별로 넣었다고 생각하면, 빨간색, 파란색, 초록색 사탕을 넣고, 다시 빼려고 뒤집으면 초록색, 파란색, 빨간색 순서로 나올 것이다.이런 구조를 LIFO(Last In First Out), 후입선출 구조라고 한다. 파이썬에서 리스트를 스택처럼 사용할 수 있지만, 그러지 않는 이유는 리스트에는 push, pop 이외의 강력한 연산이 많으나, 스택은 push, pop 만 존재한다. 이 때, 실수로 리스트에 있는 연산으로 참조, 변경을 할 수도 있기 때문에 스택이라는 클래스를 선언해서 사용한다고 한다.(굳이 싶다 그냥 정신차리고 쓰면 되는거 아닌가)
그래도 알아서 나쁠 건 없으니 한 번 해보았다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class Stack:
def __init__(self): # 스택이라는 클래스의 객체를 생성할 때 호출되는 함수
self.items = [] # self는 메서드를 호출한 객체를 가리키며 메서드는 이를 통해 객체를 조작할 수 있음.(여기서는 s)
# items라는 리스트를 통해서 스택 구현
def push(self, val): # O(1)
self.items.append(val)
def pop(self): # O(1)
try
return self.items.pop()
except IndexError:
print("stack is empty")
def top(self): # O(1)
try
return self.items[-1]
except IndexError:
print("stack is empty")
def __len__(self): # O(1)
return len(self.items)
s = Stack()
큐(Queue)
이번엔 휴지심에 빨간색 파란색 초록색 휴지뭉치를 넣는 것이다. 휴지심의 오른쪽에서만 휴지뭉치를 넣는다고하면 뒤에서 밀었을때 빨간색 파란색 초록색으로 넣은 순서대로 나오게 될 것이다. 먼저 들어간 것이 먼저 나오는 이런구조를 FIFO(First In First Out) 선입선출 구조라고 한다. 이걸 스택과 합치면 파이썬에서 제공하는 deque가 된다. 이는 양쪽에서 삽입과 삭제가 가능한 구조이다. 그래서 주로 사용하게 된다. 그럼에도 큐를 구현해 보면
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Queue:
def __init__(self):
self.items = []
self.front_index = 0
def enqueue(self, val):
self.items.append(val)
def dequeue(self):
if self.front_index == len(self.items):
print("Q is empty")
return None
else:
x = self.items[front_index]
self.front_index += 1 # 인덱스로 제어하는 것이 아닌 pop을 하게 되면 O(n)의 시간이 들게 됨.
return x
deque 에서는 다음의 메서드들을 대표적으로 제공한다.
1
2
3
4
5
6
from collections import deque
deq = deque()
deq.appendleft(10)
deq.append(0)
deq.popleft()
deq.pop()
힙(heap)
힙에대해서 공부하기에 앞서서 트리, 그 중에서도 이진트리에 대해 이해해야한다.
트리
부모 - 자식의 관계를 가지는 자료구조를 tree 라고 표현한다.
레벨 0 -> 0 레벨 1 -> 7, 5 레벨 3 -> 2, 6, 9 레벨 4 -> 5, 11, 4 노드 -> 각각의 동그라미들 루트 노드 -> 최상단 노드 : 2 링크(엣지) -> 노드사이를 이어주는 선 리프(leaf) -> 자식이 없는 노드 : 2, 5, 11, 4 높이 -> 루트노드에서 리프노드까지 가는데 거치는 링크의 수 == 레벨 : 4 경로 -> 출발노드 => … 경유노드 … => 도착노드 경로길이 -> 경로에 포함 된 링크의 수
- 이진트리 : 자식이 최대 2개인 구조
- 완전이진트리 : 마지막 레벨을 제외하고는 모두 채워져 있고, 마지막 레벨은 왼쪽에서부터 채워진 구조
- 트리의 표현법:
- 리스트 : level0 노드 -> level1노드 -> …. (같은 레벨에서는 왼쪽에서 부터) ex) A = [2, 7, 5, 2, 6, None, 9, None, 5, 11, 4, None] - 리스트(재귀) : A = [2, [7, [2, [[], []], [6, [5, 11]]]], [5, [9, [[],[4]]]]
이제 힙에 대해 알아보자. 힙이란 힙 성질을 만족하는 이진트리 이다. 정확하게는 모양과 힙 성질을 가지는 이진트리인데, 이때 모양은 완전이진트리, 힙 성질은 모든 부모노드의 key값이 자식노드의 key값 보다 작지 않아야한다.
이러한 특징 때문에 루트노드에는 가장 큰 값이 들어있게 된다. A[0] : 최대값.
여기서 주의 할 점은 실제 데이터 값은 리스트에 저장이 되어있고, 이 값이 표현하는 가상의 이진트리가 저렇게 생겼다는 것이다.
또한 A[k]의 부모노드는 A[(k-1//2)], A[k]의 자식노드는 A[2k + 1], A[2k + 2]이다. 그렇기 최대 또는 최소값을 찾을 때 시간복잡도 O(1)을 가진다는 장점이 있다. 하지만 빈칸을 다 None으로 채우기 때문에 메모리를 차지 한다는 단점 또한 공존한다.
make_heap : 힙을 만족하지 않는 걸 힙으로 만드는 행위 heapify_down : 마지막 원소부터 0 index 까지 힙 성질은 만족하도록 내려보낸다.(leaf노드는 자식이 없기 때문에 PASS)
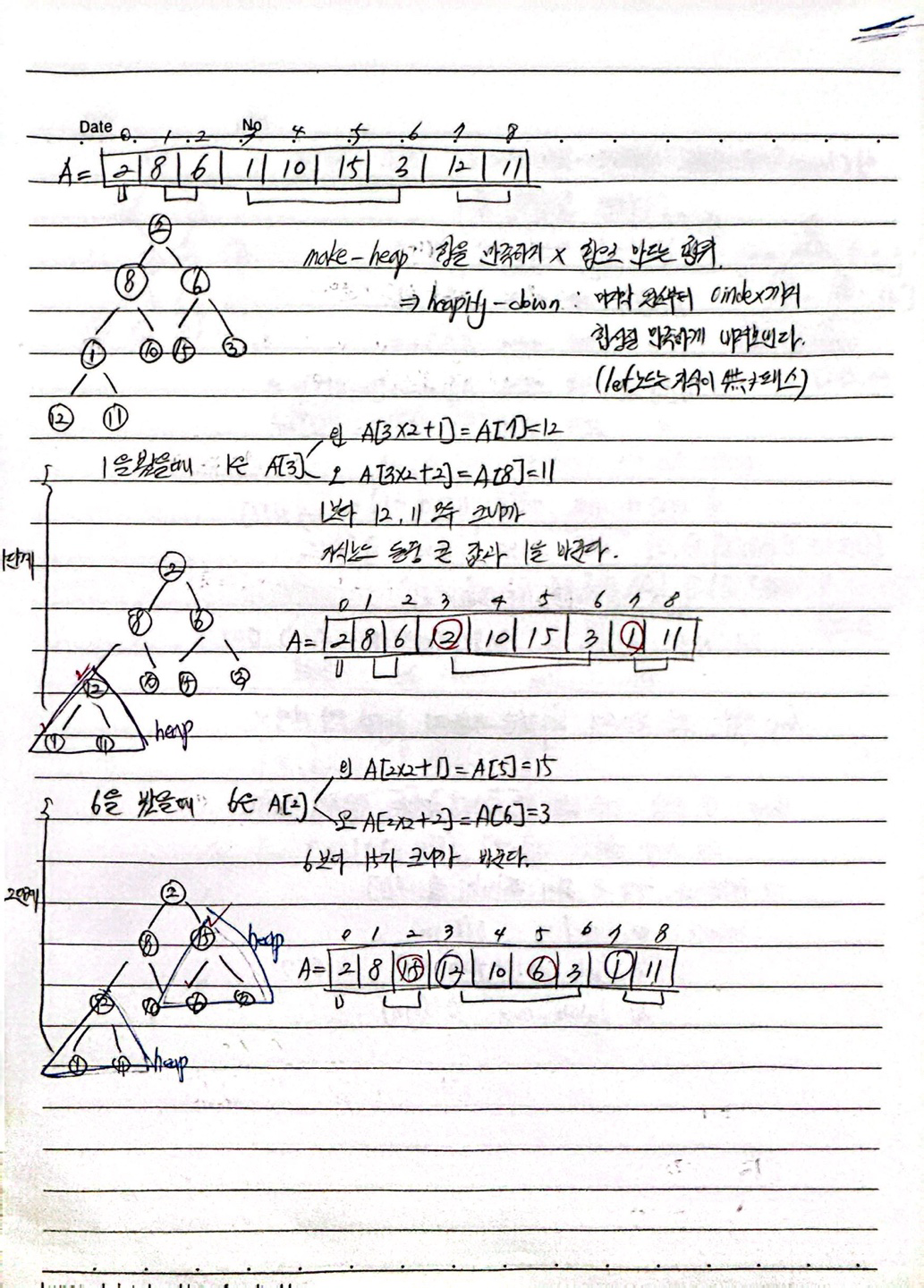
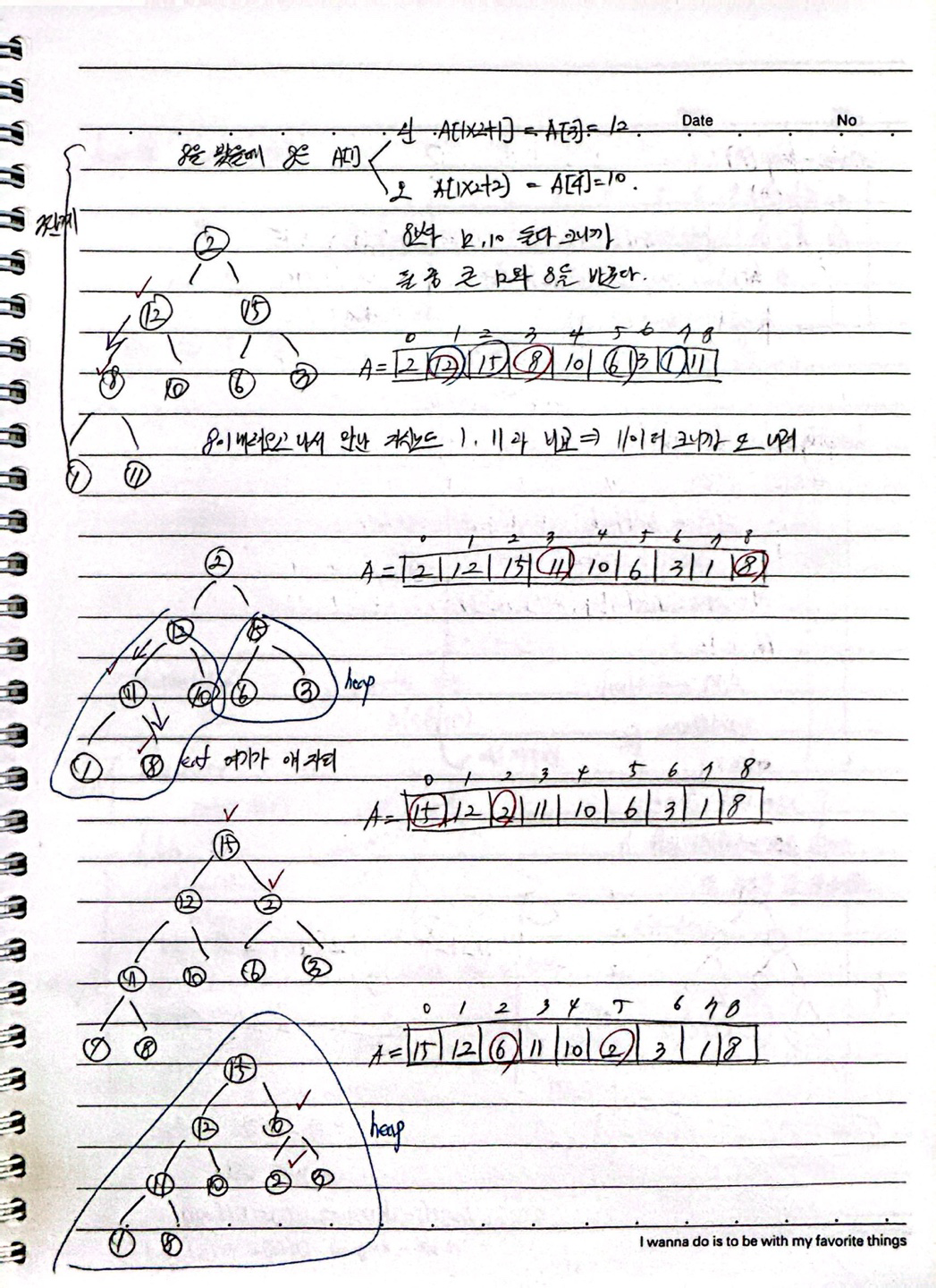
다음은 파이썬으로 make_heap을 구현 해 보았다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
class Heap:
def __init__(self, L=[]): # default: 빈 리스트
self.A = L
self.make_heap() # A의 값을 힙성질이 만족되도록
# make_heap 함수 호출 (추후설명)
def __str__(self):
return str(self.A)
def make_heap(self):
n = len(self.A)
for k in range(n-1, -1, -1): # A[n-1] → A[0] 순서로
self.heapify_down(k, n)
def heapify_down(self, k, n):
# n = 힙의 전체 노드수 [heap_sort를 위해 필요함]
# A[k]를 힙 성질을 만족하는 위치로 내려가면서 재배치
while 2*k+1 < n: # 조건문이 어떤 뜻인가?
L, R = 2*k + 1, 2*k + 2 # L,R은왼쪽,오른쪽자식노드
if self.A[L] > self.A[k]: # 세 노드의 최대 값의 인덱스 찾기
m=L
else:
m=k
if R < n and self.A[R] > self.A[m]:
m=R
# m = A[k], A[L], A[R] 중 최대값의 인덱스
if m != k: # A[k]가최대값이아니면힙성질위배
self.A[k], self.A[m] = self.A[m], self.A[k]
k=m
else:
break

힙의 연산으로는 insert(), delete_max(), find_max()등이 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def heapify_up(self, k): # 올라가면서 A[k]를 재 배치
while k>0 and self.A[(k-1)//2] < self.A[k] :
self.A[k], self.A[(k-1)//2] = \
self.A[(k-1)//2], self.A[k]
k = (k-1)//2
def insert(self, key):
self.A.append(key)
self.heapify_up(len(self.A)-1)
def delete_max(self):
if len(self.A) == 0:
return None
key = self.A[0]
self.A[0], self.A[len(self.A)-1] = \
self.A[len(self.A)-1], self.A[0] self.A.pop() # 실제로 리스트에서 delete!
heapify_down(0, len(self.A)) # len(A) = n-1 return key
def find_max(self):
max = self.A[0]
return max
insert의 경우 가장 마지막 레벨의 가장 오른쪽 빈 칸에 삽입되어 루트 노드까지 올라갈 수 있기 때문에 O(logn)의 시간 복잡도를 가지며, delete_max 의 경우 가장 큰 값을 삭제 후 리턴하는 것이 때문에 O(logn)의 시간복잡도를 가진다.
이렇게 힙은 insert, find_max, delete_max에 최적화 된 자료구조이며, 응용하여 min_heap도 구현할 수 있다.
우선순위 큐(Priority Queue)
사실 우선순위 큐는 실존하는 자료구조가 아니라, 우선순위가 먼저 빠져나가는 형태를 가진 자료구조를 의미하는 용어이며, 대표적으로 힙을 통해서 구현이 가능하다.
해시 테이블
O(1)에 삽입, 삭제, 탐색이 가능한 자료구조로, Key 값을 f(key)의 해시함수를 통하여 index에 매핑하는 구조이다. 마치 서랍에 양말, 옷, 속옷 등으로 따로 넣는 것과 같다.
해시 테이블의 3가지 중요점은
- Table(list)
- Hash Function
- Collision resolution method 해시 테이블은 예를 들어 학번 : “정재욱” 의 방식으로 key에 대한 value값이 특정 index로 매핑이 되는 형태인데 이 형태 때문에, 해시 함수를 통해 index를 구하더라도 같은 index에 여러개의 key가 매핑되는 경우가 생긴다. 유한한 크기의 해시 테이블에 무한한 수의 가능한 키들을 매핑해야 하기 때문에 충돌이 발생할 수 밖에 없다. 이를 해결하기 위해 체이닝(Chaining)을 사용한다.
- 체이닝 : 하나의 index에 여러개의 key값이 매핑 될 경우, linked list를 이용하여 같은 주소로 매핑 된 원소들을 하나로 이어서 관리한다. 이 때 원소의 삽입은 L-L의 맨 앞에 삽입을 한다(맨 뒤에 삽입시 연결리스트를 따라 뒤까지 이동해야 하기 때문)
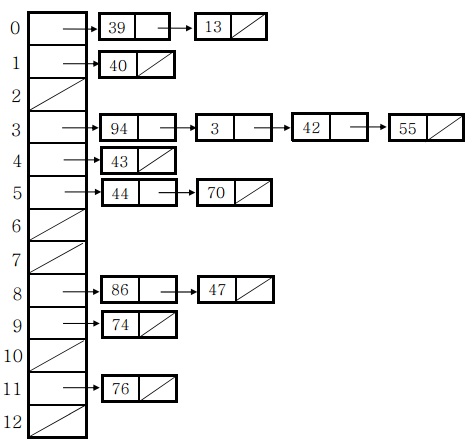 이는 하나의 주소에 Key값이 몰리게 되면 검색의 효율이 떨어지게 되는 단점이 있다. 파이썬에서는 dictionary와 set이 해시 테이블을 사용한다.
이는 하나의 주소에 Key값이 몰리게 되면 검색의 효율이 떨어지게 되는 단점이 있다. 파이썬에서는 dictionary와 set이 해시 테이블을 사용한다.
연결리스트(Linked List)
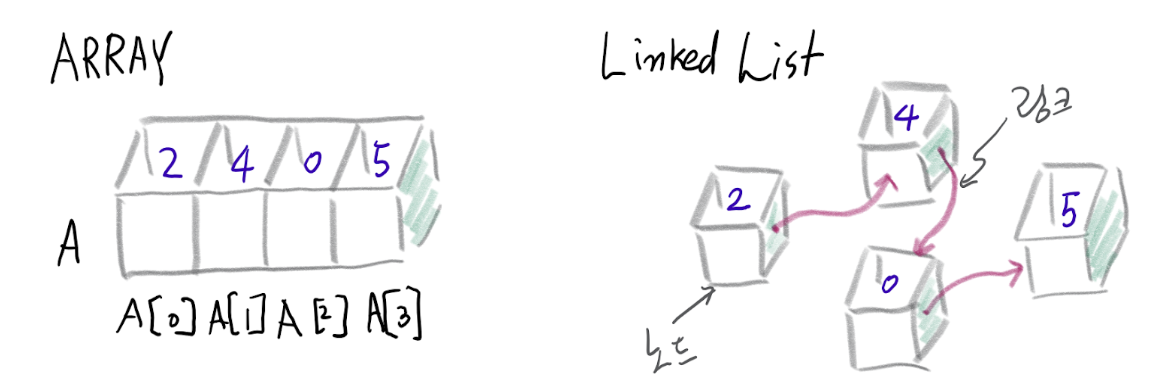
배열은 미리 크기가 정해진 채로 연속된 공간에 메모리를 차지하여, 인덱스로 값을 자주 참조하게 되는 경우에 유리하다. 그에 반해 연결리스트는 크기가 정해지지 않고, 삽입과 삭제가 자주 반복 되는 경우에 적합하다. 그림에서 보는 노드는 data값(key)와 다음값의 주소(link)의 쌍으로 이루어져 있다(value가 있기도 함). 마지막 노드의 다음 링크를 따라가면 None을 마주치게 된다. 이렇게 노드와 링크로 이루어진 자료구조가 연결리스트 이며, 값들이 메모리 상에서 연속적이지 않고 흩어져 있기 때문에, 탐색을 위해서는 head노드 부터 링크를 따라서 목표까지 가야하는 O(n)의 시간 복잡도를 가진다. 하지만 삽입, 삭제의 경우는 다르다. 새로운 값을 insert 할 때 배열은 삽입 후 의 값을 한칸 씩 다 밀어내야 하여 O(n)의 시간복잡도를 가지지만, 링크드 리스트는 삽입할 부위의 앞 뒤 링크가 새로운 요소를 가리키게만 바꾸면 되는 O(1)의 시간복잡도를 가진다. 연결리스트에는 한방향 연결리스트와 양방향 연결리스트가 존재한다. 둘의 차이는 노드가 양쪽의 링크를 가지고 있냐, 한쪽만드로 링크를 가지고 있냐이다.
1
2
3
4
5
6
7
class Node:
def __init__(self, key=None, value=None):
self.key = key # 노드를 다른 노드와 구분하는 key 값
self.value = value # 필요한 경우 추가 데이터 value
self.next = None # 다음 노드로의 링크 (초기값은 None)
def __str__(self): # print(node)인 경우 출력할 문자열
return str(self.key) # str((self.key, self,value))
만약 연결 리스트에서 각 노드들의 값과 위치를 다 알고 있다면, 각각의 노드마다 변수가 생기게 된다. 때문에 head 노드에 대해서만 알고 있다.
한방향 연결리스트
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class SinglyLinkedList:
def __init__(self):
self.head = None # 연결리스트의 가장 앞의 노드 (head)
# 초기값은 None
self.size = 0 # 리스트의 노드 개수 (필요하다면)
def __iter__(self): # generator 정의
# 연결리스트의 노드를 for 문 형식으로 접근 위해
v = self.head
while v != None:
yield v # return 과 같은 개념으로 yeild를 가진 함수를 generator라고 부름
v = v.next
def __str__(self): # 연결 리스트의 값을 print 출력
return " -> ".join(str(v) for v in self)
# generator를 이용해 for 문으로 노드를 순서대로
# 접근해서join함-key값사이에->넣어출력
# L-L에서 for x in L:
# print(x) 의 형태가 가능하도록 해주는 것이 generator
def __len__(self):
return self.size # len(A) = A의 노드 개수 리턴
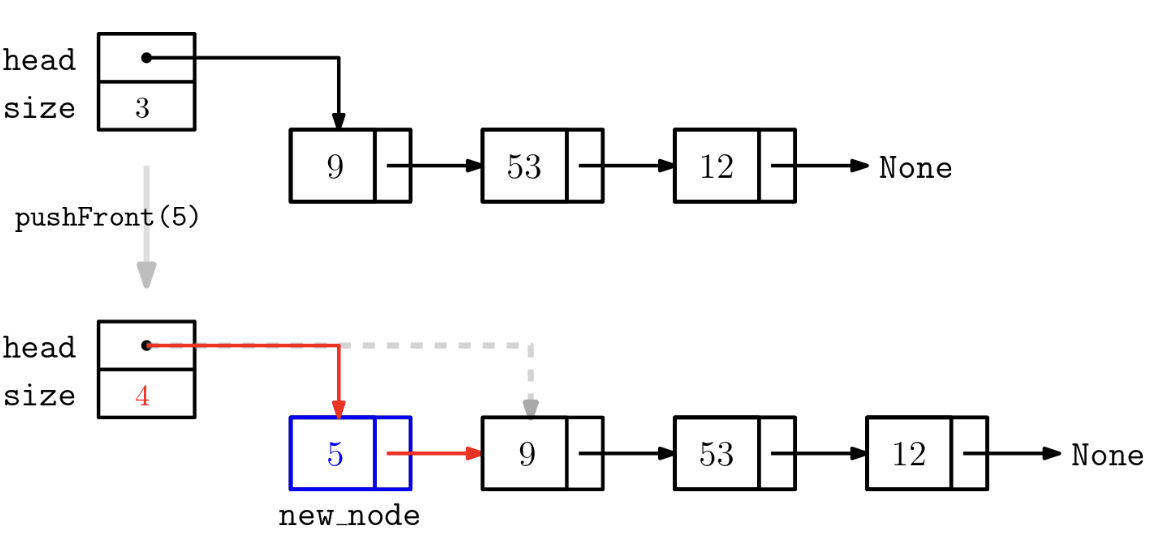
삽입연산 중 pushFront는 head앞에 새로운 노드를 생성하여 삽입하고 head노드로 만든다.
1
2
3
4
5
def pushFront(self, key, value=None):
new_node = Node(key, value)
new_node.next = self.head
self.head = new_node
self.size += 1
pushBack은 마지막 노드의 다음에 삽입되므로 tail 노드의 next링크가 새로운 노드로 변경 되어야 하며, 빈 리스트일 경우에는 head노드가 되어야 한다.
1
2
3
4
5
6
7
8
9
10
def pushBack(self, key, value=None):
new_node = Node(key, value)
if self.size == 0:
self.head = new_node
else:
tail = self.head
while tail.next != None: # tail 노드 찾기
tail = tail.next
tail.next = new_node
self.size += 1
삭제 연산 중 popFront는 head노드를 삭제하고 해당 key값을 반환하는 함수로 빈 리스트 일 경우 None을 반환한다.
1
2
3
4
5
6
7
8
9
10
11
def popFront(self):
if self.size == 0:
return None
else:
key = x.key
x = self.head
self.head = x.next
self.size = self.size - 1
del x
return key
popBack은 tail노드를 찾아 지우고 그 전 노드의 링크도 수정해주어야한다. 그렇기에 prev노드 또한 알아야한다. 그렇기 때문에 prev노드와 tail노드 나란히 이동하며 prev를 찾는다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def popBack(self):
if self.size == 0:
return None
else:
prev, tail = None, self.head
while tail.next != None:
prev = tail
tail = tail.next
if prev == None:
self.head = None
else:
prev.next = tail.next
key = tail.key
del tail
self.size -= 1
return key # or return (key, value)
탐색 연산은 head 부터 next링크를 따라가면서 찾는다.
1
2
3
4
5
6
7
def search(self, key):
v = self.head
while v != None:
if v.key == key:
return v
v = v.next
return v
양방향 연결리스트
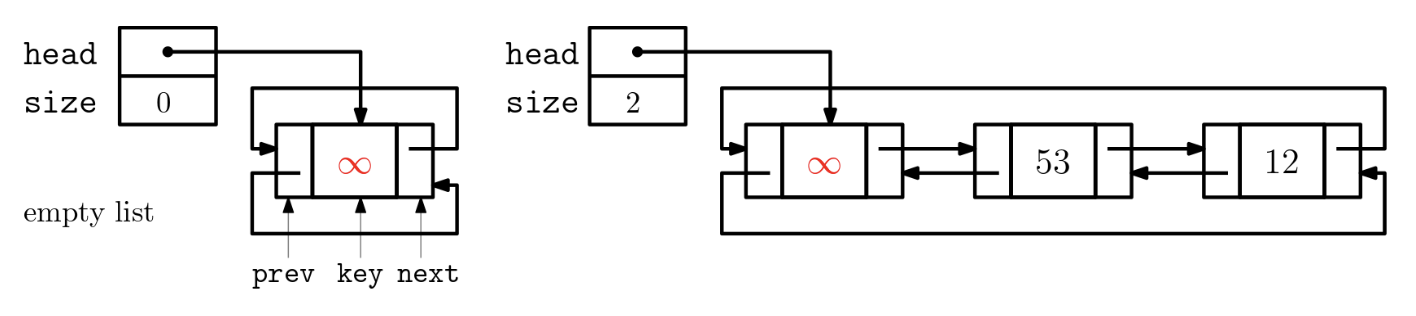
한방향 연결리스트의 경우 이전 노드에 대한 링크가 없어서 찾기위해선 head노드 부터 탐색을 해야 하는 단점이 있었다. 이를 보완한 것이 양방향 연결리스트 이다. link의 수가 2배로 는다는 단점이 있지만 삭제연산 수행시 O(1)의 시간복잡도를 가질 수 있다. 양방향 리스트 중에서도 삽입과 삭제가 간단한 원형 양방향 리스트에 대해서만 다루겠다.
빈리스트를 만들 때 꼭 dummy node를 만들어 어디가 시작인지를 나타낸다.
1
2
3
4
5
6
class Node:
def __init__(self, key=None):
self.key = key # 노드에 저장되는 key값
self.next = self.prev = self # 자기로 향하는 링크
def __str__(self): # print(node)인 경우 출력할 문자열
return str(self.key)
1
2
3
4
5
6
7
8
9
10
11
12
def __init__(self):
self.head = Node() # 더미 노드
self.size = 0
def __iter__(self):
v = self.head.next
while v != self.head:
yield v
v = v.next
def __str__(self):
return "<->".join(str(item) for item in self)
def __len__(self):
return self.size
splice 연산 조건1 : a와 b가 동일하거나 a다음에 b여야 한다. 조건2 : head노드와 x는 a~b에 포함되면 안돼. 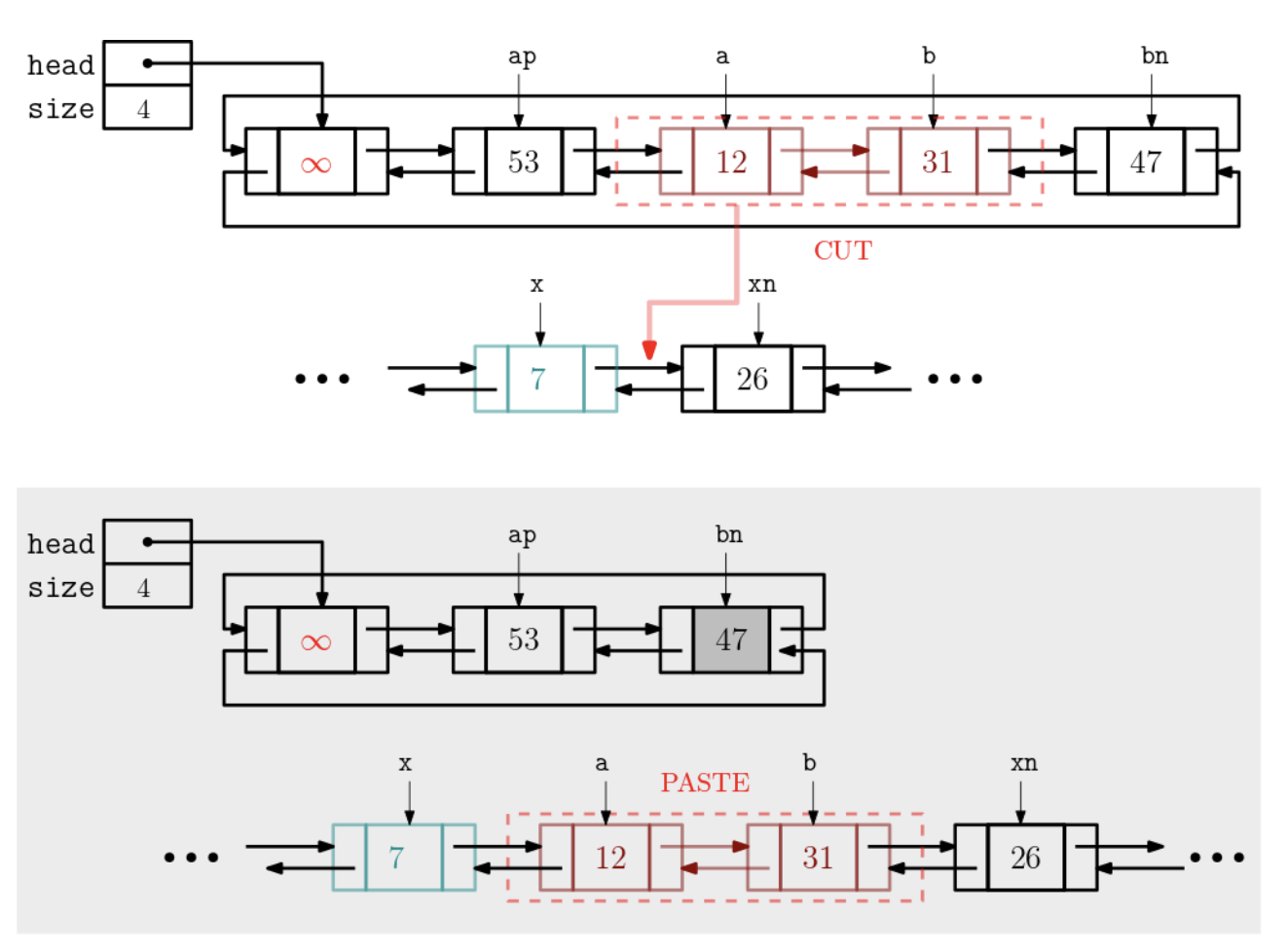
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def splice(self, a, b, x):
if a == None or b == None or x == None:
return
ap = a.prev
bn = b.next
xn = x.next
ap.next = bn # a~b 잘라서
bn.prev = ap
xn.prev = b # x의 뒤에 삽입
b.next = xn
a.prev = x
x.next = a
이외의 연산은 splice연산을 이용하여 구현한다.
1
2
3
4
5
6
7
8
9
10
11
12
def moveAfter(a, x): # 노드 a를 노드 x 뒤로 이동
splice(a, a, x) # a, x는 다른 연결리스트에 있어도 돼
def moveBefore(a, x): # 노드 a를 노드 x 뒤로 이동
splice(a, a, x.prev)
def insertAfter(x, key): # 노드 x 뒤에 데이터가 key인 새 노드를 생성해 삽입
moveAfter(Node(key), x)
def insertAfter(x, key): # 노드 x 앞에 데이터가 key인 새 노드를 생성해 삽입
moveBefore(Node(key), x)
def pushFront(key): # 데이터가 key인 새 노드를 생성해 head 다음(front)에 삽입
insertAfter(self.head, key)
def pushBack(key): # 데이터가 key인 새 노드를 생성해 head 이전(back)에 삽입
insertBefore(self.head, key)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def remove(self, x):
if x == None or x == self.head: # 조건체크
return
x.prev.next, x.next.prev = x.next, x.prev # x를 떼어냄
def popFront(self):
if self.isEmpty():
return None
key = self.head.next.key
self.remove(self.head.next)
return key
def popBack(self):
if self.isEmpty():
return None
key = self.head.prev.key
self.remove(self.head.prev)
return key
출처 : https://coding6467.tistory.com/14 한국외대-컴퓨터공학부-신찬수 교수님 강의 자료 중 일부