CSAPP › CSAPP 시스템 하드웨어 구조와 시간복잡도(Week1_Day4)
오늘은 컴퓨터 시스템 1.1 ~ 1.4 장을 읽어보았다.
1장에서는 hello프로그램의 생성 -> 시스템에서실행 -> 메세지 출력 -> 종료 의 수명주기를 간단히 설명했다.
hello 프로그램의 생성
프로그래머가 에디터로 작성한 소스파일로 시작한다고 한다.
이 소스 파일은 바이트 단위로 구성된다고 한다.
비트 : 0 또는 1로 표시되는 가장 기본이 되는 단위. 바이트 : 8비트 단위로 구성되어 정보를 표현하는 기본이 되는 단위. 각 바이트는 프로그램의 텍스트 문자를 나타낸다.
대부분 텍스트 문자를 아스키 표준을 사용하여 나타내는데 알고리즘 풀면서 몇번 마추쳤던 이름이라 익숙하긴 했는데 궁금해서 찾아봤다.
아스키 : ANSI라는 곳에서 사용한 부호체계라는데 그게 중요한 건 아니고, 7비트를 사용해서 2^7 = 128개의 문자를 표현 했다고 한다. 아까 1바이트는 8비트라고 했었는데 그럼 남은 1비트는 뭐냐 했더니, 패리티 비트로 남겨 1의 수가 홀수이면 1아니면 0 이런식으로 데이터 손실을 막기 위한 지표로 사용했다고 한다. 아무튼 그렇게 때문에 2바이트 이상의 문자는 표현을 할 수가 없다. 대표적으로 한글 같은 경우에는 1바이트로는 한글을 다 표현 할 수가 없기 때문에, 해외에서 가져온 문서가 글씨가 깨지는 경우가 많았다고 한다. 이후 2바이트를 사용하는 유니코드가 등장하면서 해결되었다고 한다.
그렇기에 앞서 작성한 hello.c는 연속된 바이트 들로 파일에 저장된다. 얘처럼 오직 아스키 문자로만 이루어진 파일을 텍스트 파일이라 부르고 그 외에는 모두 바이너리 파일이라고 한다. 이들을 구분하는 방법은 이들을 바라보는 컨텍스트에 의해서 이다.
컨텍스트 : 이게 또 뭔소린가 했더니 별 얘기가 아니고, 1번 페이지에서는 로그인을 한 유저 였던 한 객체가 2페이지에서는 게시글을 작성한유저 가 될 수 있다, 바라보기에 따라 같은 사용자가 다를 수 있다 라는 뜻이다.
고급언어 : 추상화가 잘 되어 있어서 사람이 쉽게 이해 할 수 있는 수준의 언어 저급 언어 : 추상화 수준이 낮아서 하드웨어에 가까운 언어
앞서 작성한 hello.c(소스파일)는 인간이 바로 이해 할 수 있는 고급 프로그램으로 이를 실행하기 위해서는 4단계(컴파일 시스템)를 거쳐서 실행파일인 hello가 된다.
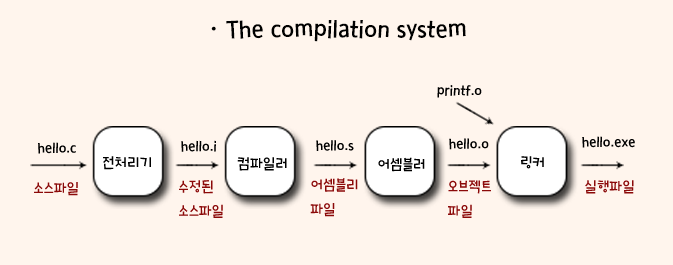
전처리 단계 : #으로 시작하는 문장을 전처리기라고 부르는데 #include
는 앞선 소스파일을 번역하기 위해서 시스템 헤더파일인 stdio.h를 직접 삽입하라고 지시하는 것이다. 이를 통해 hello.i가 생성된다.
컴파일 단계 : 이제 컴파일러를 통해 사람이 이해하는 언어로 작성한 내용이 어셈블리어로 변역 된다. 이를 통해 hello.s가 된다.
- 어셈블리어 : 기계어와 일대일로 매칭되어 기계어가 너무 불편하기 때문에 비교적 간단한 어셈블리어로 짜는 것. 때문에 중간언어라고도 부른다.
어셈블리 단계 : 어셈블러(as)가 기계어 인스트럭션으로 번역하고, 이를 재배치 가능의 목적 프로그램으로 묶어서 목적파일(hello.o)에 저장한다.
- 목적 파일: 소스파일을 컴파일 한 후 생성되는 중간 산출물인데, (바이너리 파일이다) 링커에 의해 다른 목적파일과 묶여서 실행가능한 프로그램이나 라이브러리로 결합 될 준비가 된 상태이다. 모든 파일을 한 번에 컴파일 하는 것이 아니라, 개별적으로 컴파일을 하여 목적파일을 생성함으로서 혹시 하나의 파일에 수정이 있을 때 수정된 파일만 다시 컴파일하고 변경되지 않는 목적파일은 재사용 하여 컴파일 시간을 크게 단축 시키는 목적이 있다.
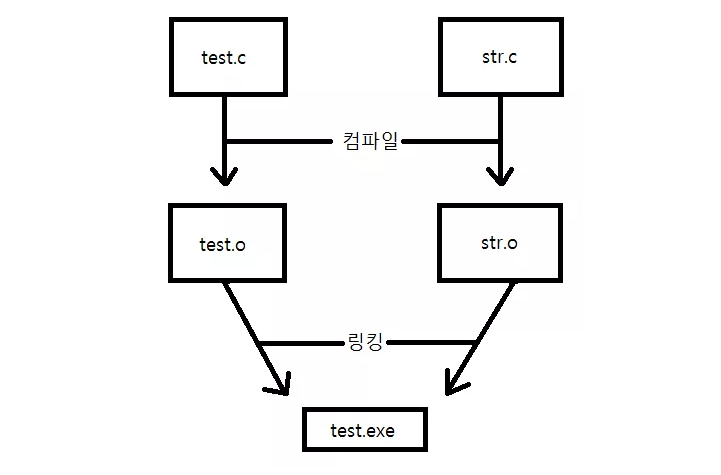
링크 단계 : 링커는 각각의 목적 파일을 하나의 실행파일이나 라이브러리로 묶어주는 작업이다. 이를 통해 실행가능 파일이 되어 메모리에 적재되었다 시스템에 의해 실행된다. 링킹 과정에서 특정 파일에 있는 함수들이 어디에 있는지 찾는 과정을 거치기 때문에, 다른 파일에서 작성한 함수를 호출하더라도 사용할 수 있게 된다.
위의 과정을 통틀어서 빌드라고 하며, 그 과정에서 사용하는 일련의 도구들이 컴파일 시스템이다.
시스템의 하드웨어 구조
버스
시스템 내를 관통하는 전기적 배선군. 즉 그냥 데이터가 지나다니는 길이다. 일반적으로 워드 라고 하는 고정 크기의 바이트 단위로 전송하며, 한 개의 워드를 구성하는 바이트 수는 시스템마다 32비트, 64비트 등 기본 시스템 변수로 가진다. 한 개의 통신만 허용하는 특징이 있다(병목).
- 시스템 버스 : CPU, Chache Memory, Memory 등 데이터 전송 버스
- I/O 버스 : 상대적으로 느린 입출력 장치(키보드, 마우스, 프린터 등)들로 부터 데이터를 전송하는 버스
입출력 장치
키보드 마우스 모니터, 저장소드라이브 등이 해당한다.
메인메모리
프로세서가 프로그램을 실행하는 동아 데이터와 프로그램을 모두 저장하는 임시 저장장치이다. 물리적으로는 RAM(Random Access Memory)을, 논리적으로는 메모리는 연속적인 바이트 배열로 각각 0부터 시작해서 고유의 주소(배열의 인덱스)를 가진다.
프로세서
메인 메모리에 저장된 인스트럭션을 해독(실행)하는 엔진이다. 전원이 공급되는 순간부터 PC값이 가리키는 곳의 인스트럭션을 반복하고 PC값이 다음 인스트럭션을 가리키도록 업데이트 한다.
- 인스트럭션 요청으로 CPU가 작업 실행하는 예시
- 적재(load): 메인 메모리에서 레지스터에 한 바이트 또는 워드를 이전 값에 덮어쓰는 방식으로 복사
- 저장(store): 레지스터에서 메인메모리로 한 바이트 또는 워드를 이전 값에 덮어쓰는 방식으로 복사
- 작업(operate) : 두 레지스터의 값을 ALU로 복사하고 두개의 워드로 수식연산을 수행 한 뒤 결과를 덮어쓰기로 레지스터에 저장
- 점프(jump) : 인스트럭션 자신으로부터 한 개의 워드를 추출하고, PC에 덮어쓰기 방식으로 복사.
- 레지스터 : 작업과 프로그램을 효율적으로 실행하는 데 사용할 수 있는 빠른 메모리
- PC(program counter) : CPU가 수행해야 할 메모리 주소를 담고있는 레지스터
- 인스트럭션(instruction) : 컴퓨터가 이해할 수 있는 명령어 -CU(Control Unit) : 명령제어장치, 입력된 명령어를 해독하여 cpu를 통제
- ALU(Arithmetic Logic Unit) : 산술연산장치라고 부르며, CU로 부터 명령을 받아 CPU로 들어온 모든 데이터들을 연산.
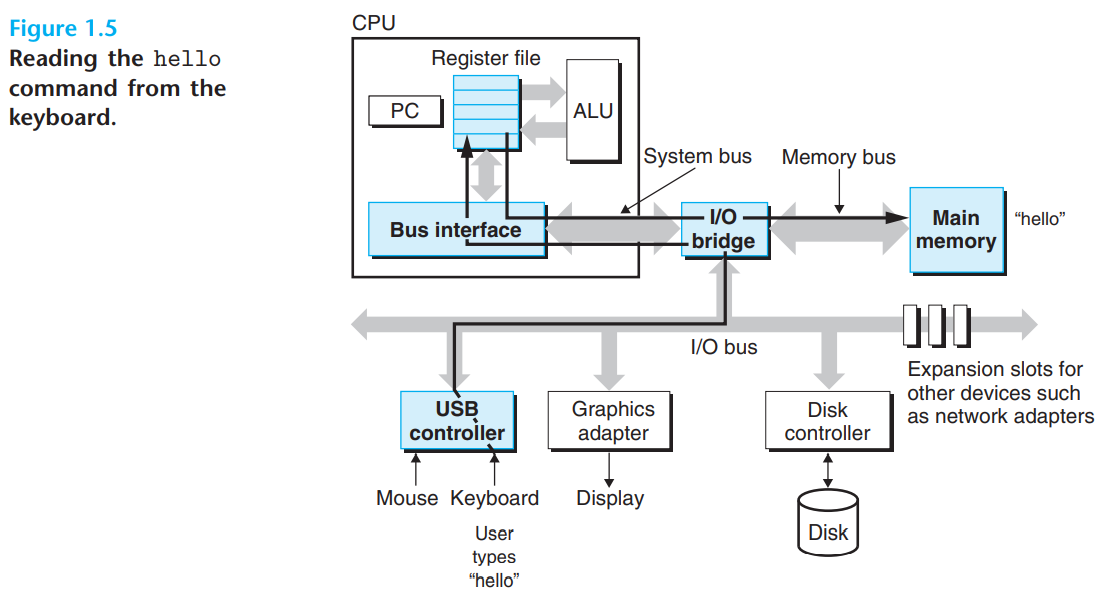
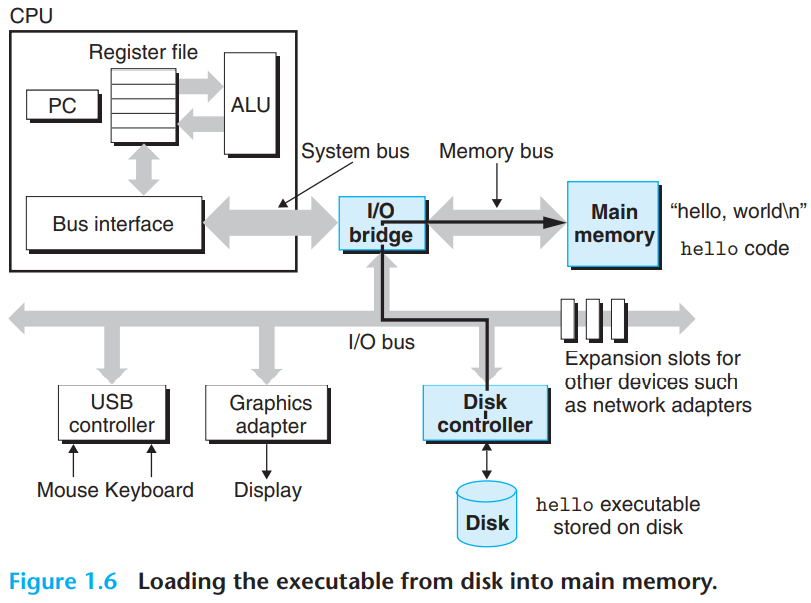
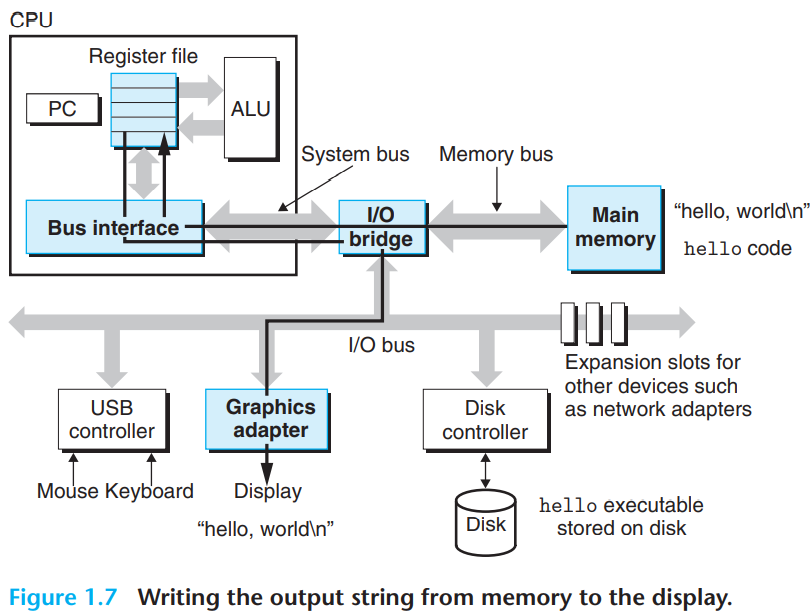
hello 프로그램의 실행 과정
CPU는 hello가 입력되길 기다리고 있다가 유저가 “hello”를 입력하면, 각 문자를 레지스터에 읽어들인 뒤 메모리에 저장 -> 엔터를 누르게 되면 쉘은 실행파일 hello를 디스크에서 실행파일 hello를 디스크에서 메인메모리로 로드 한다.이 때 DMA라는 직접 메모리 접근 기법을 사용하여 프로세서를 거치지 않고 이동하며, hello object file이 메모리에 load가 되면 cpu는 hello 프로그램의 main 루틴의 기계어 instruction을 실행하게 되고, 이 instruction들은 “hello, world\n” 라는 스트링을 메모리에서 레지스터파일로 복사했다가 디스플레이 장치로 전송한다.
시간복잡도
입력값과 연산 수행 시간의 상관관계를 나타내는 척도 점근적 표기법 3가지로 시간복잡도를 나타낼 수 있다.
최상의 경우 : 오메가 표기법 평균의 경우 : 세타 표기법 최악의 경우 : 빅오 표기법
이 중에서 주로 빅오 표기법을 사용한다. 그 이유는 빅오 표기법의 특성 상, 최악의 경우를 고려하여 알고리즘의 성능을 평가 할 수 있고, 연산 수를 정확하게 표현 하지는 않지만 상한선을 제공하기 때문에 이해하기 편하며, 상수시간 복잡도 보다 입력(n)의 크기 증가에 따른 경향을 큰 입력에서도 잘 나타내기 때문에 사용한다.
빅오 표기법(Big-O)
빅오 표기법은 불필요한 연산을 제거하여 알고리즘을 쉽게 분석 할 목적으로 사용한다.
시간복잡도 : 입력된 N의 크기에 따라 실행되는 조작의 수를 나타낸다. 공간복잡도 : 알고리즘이 실행 될 때 사용하는 메모리공간을 나타낸다.
근래 메모리의 발전으로 인해 공간복잡도의 중요도는 낮아졌다.
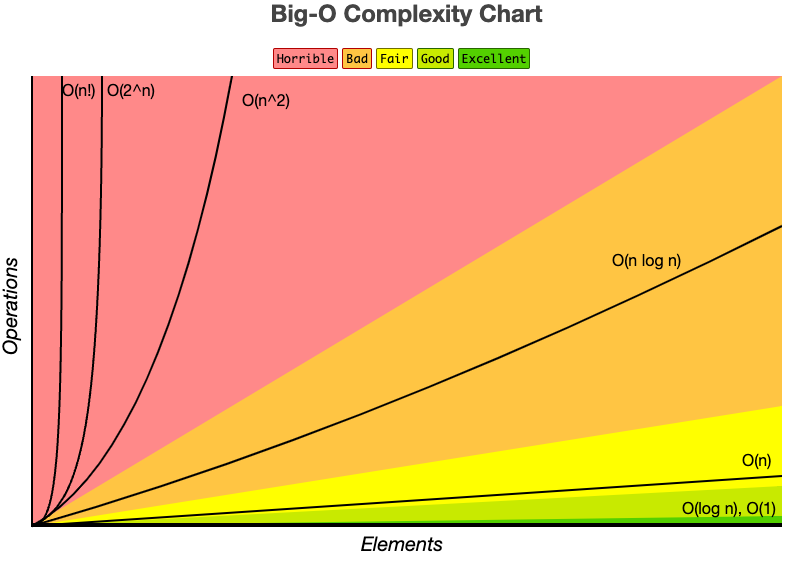
알고리즘을 수행하는데 필요한 연산을 보여준다. 실행시간이 아닌 연산수치로 성능을 판별하는 이유는 실행시간은 하드웨어, 사용언어에 따라 편차가 크게 달라지기 때문이다.
다음은 왼쪽부터 실행시간이 빠른 순서이다.
O(1) < O(logN) < O(N) < O(NlogN) < O(N^2) < O(2^N) < O(N!)
O(1) : 입력 데이터에 상관 없이 언제나 일정한 시간이 걸린다.
O(logN) : 대표적으로 이진 탐색이 있으며 한 번 수행할때마다 처리 할 값이 반씩 사라지는 알고리즘의 시간복잡도 이다. (2^k = N => k = logN)
O(N) : 입력 데이터 N의 크기에 비례하여 처리 시간이 증가한다.
O(NlongN) : 대표적으로 병합 정렬이 있다. 1개가 남을때까지 계속해서 반으로 나누는 행위(N개의 원소를 반으로 나눠서 1개로 만들기 = 2를 몇 번 곱해야 N이 나오는가)logN 과 병합하면서 N개의 원소를 모두 한 번씩 병합하기 때문에 NlogN이 된다.
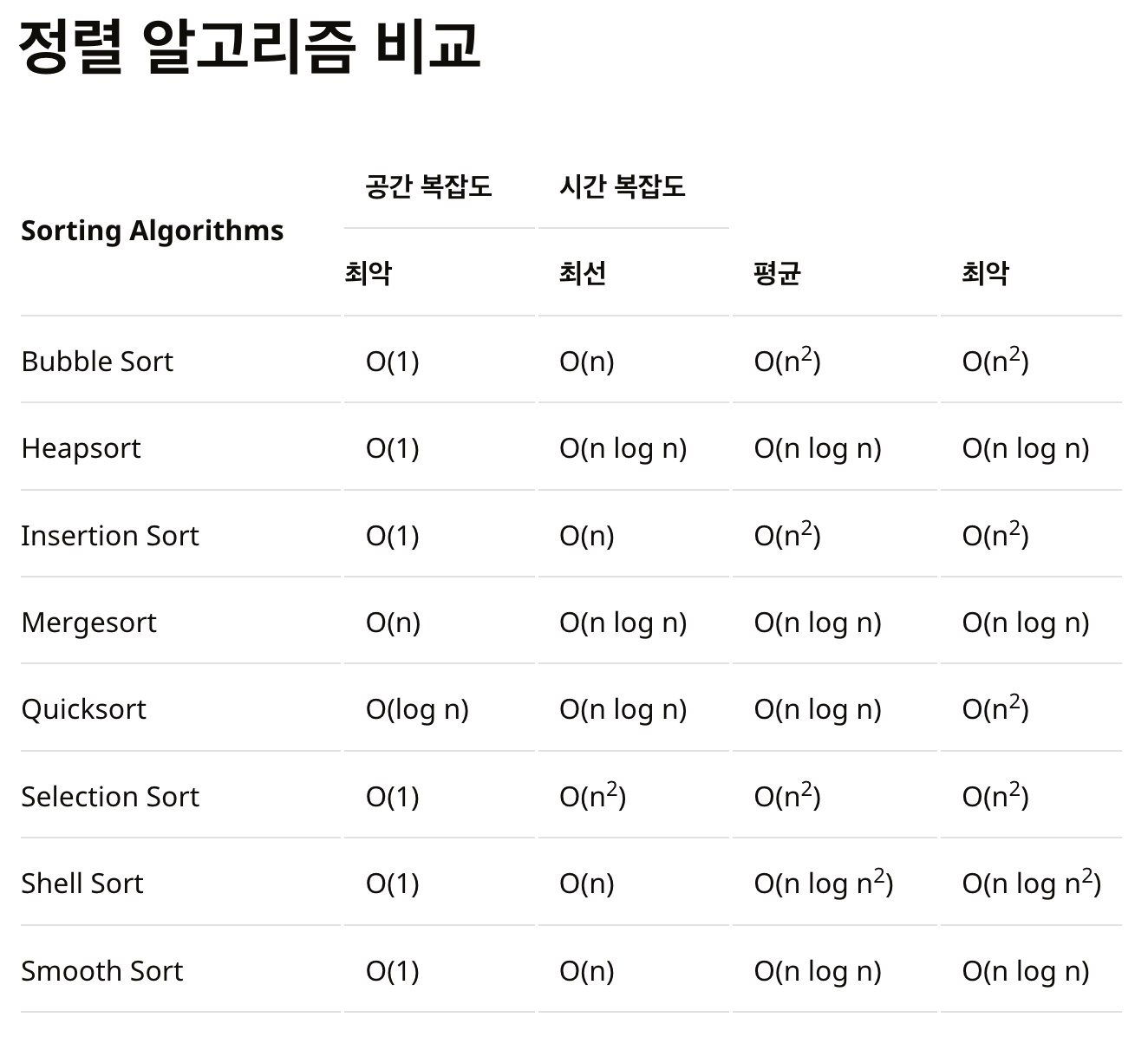
O(N^2) : 보통 이중 for문이 있는 경우이며 각 원소를 모든 다른 원소와 비교하면 N^2이 된다. 대표적으로 버블정렬, 선택정렬, 삽입정렬이 있다.
O(2^N) : 대표적으로 재귀로 표현한 피보나치 수열이 있다. 함수가 호출될 때마다 두번씩 호출 한다.
O(N!) : 대표적으로 순열이 있다. N개의 원소를 가지는 배열을 정렬하는 수이다.
시간복잡도 계산 요령:
하나의 루프를 이용하여 단일 요소 집합을 반복 : O(N)
컬렉션의 절반 이상을 반복 : O(N/2) -> O(N)
두 개의 다른 루프를 사용하여 두 개의 개별 컬렉션을 반복 -> O(N + M) -> O(N)
두 개의 중첩 루프를 통해 단일 컬렉션을 반복 -> O(N^2)
두 개의 중첩 루프를 통해 두 개의 다른 컬렉션을 반복 -> O(N^2)
컬렉션 정렬을 사용하는 경우 : O(nlogn)
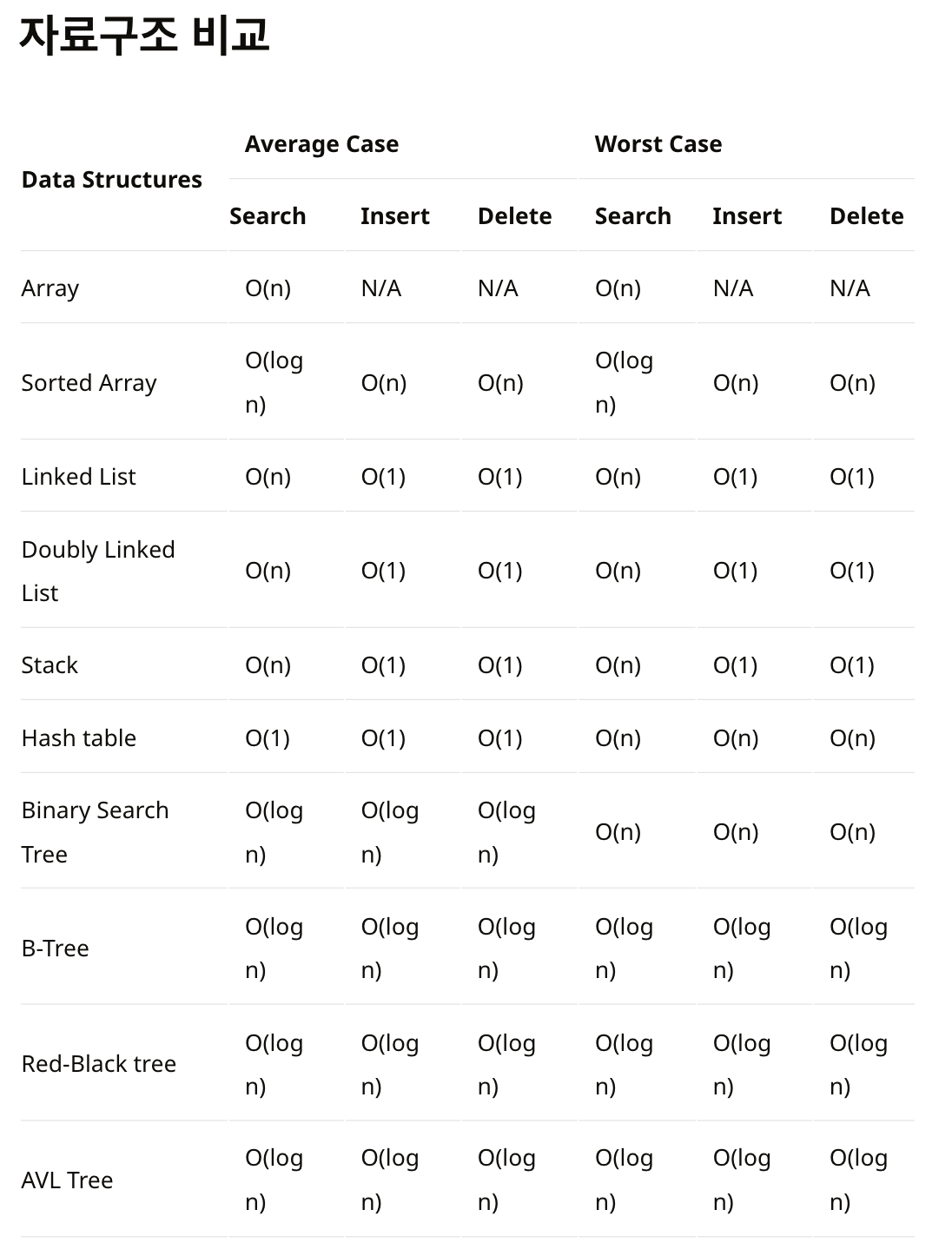
출처 : https://gamestory2.tistory.com/131 https://sseddi.tistory.com/84 https://code4human.tistory.com/110 https://www.bigocheatsheet.com/